Overview

The Big data world is slowly transitioning into capturing event based delta processing and there are many advantages associated with the concept
-
Change data capture (capture changes to your datasources in the absence of a watermark or a delta column)
-
Event sourcing (use incremental data reducing ingress/egress costs)
-
Internal/external dashboards (stream source information directly into dashboards creating analytic insights)
Let us discuss in details a couple of the above advantages.
Change data capture
Applying a layer of federated query capability on a distributed layer can be challenging if all the incoming data sources are not well co-ordinated. The currency of the data in the platform is a key consideration for deriving value from distributed systems. The late arrival of data or data sources falling out of sync with each other create a lot of disparities and remediation needs in the modern data platform.
The diagnosis of such issues have to begin with the “source of truth” and eventually any changes applied to the raw data have to quickly and effectively find their way to the insights and analytics layer.
By loading the change events into Zetaris using Debezium and Kafka, you’ll be able to query every datasource change for the raw data in real-time and propagate it without loss of currency into the Analytics layer.
Event sourcing
Event sourcing is the means of understanding the state of the system in comparison to a specific point in time in the past. The benefits of event sourcing far outweighs the traditional method of comparing records using hashing mechanisms wherein there is a sustained need for a hash key or a watermark to uniquely identify records. in this example , we are using Debezium to query across an unindexed and hashed database to capture changes in state and propagate it in realtime to Zetaris.
The change events can either be materialised into a permanent view which can reliably hold a log of all the record changes that have happened since inception and continue to be captured in real-time.
Key Components
Apache Kafka - Transport
Debezium - Change Data Capture
Zetaris - Aggregation
Pre-Requisites
The solution requires installing and configuring Java, Apache Kafka, Kafka Connect, Debezium and SQL Server on Virtual Machine.
Linux VM
Java is a required dependency since the Kafka libs run on Java. To install Java and add it to the environment variables for the VM, use the commands listed below.
> sudo yum install java-1.8.0
> export JAVA_HOME=/usr/lib/jvm/jre-1.8.0
Apache Kafka
Download and install latest version of Apache Kafka on Linux VM
> mkdir kafka/
> cd kafka
> wget https://archive.apache.org/dist/kafka/3.3.1/kafka-3.3.1-src.tgz (asc, sha512)
> tar -xzf kafka-3.3.1-src.tgz (asc, sha512)
> cd kafka-3.3.1-src
Debezium
Debezium is an open source distributed platform for change data capture,It captures changes in database(s) and publishes those changes to topics in Kafka.
In the kafka-3.3.1-src folder that we ended the last set of commands with, we will download the Debezium libraries under libs folder. Then, we will untar it into your Kafka Connect environment before moving it to the directory of the plugins folder. Lastly, we will run the command to set our plugin path for Kafka Connect.
> wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-sqlserver/2.0.1.Final/debezium-connector-sqlserver-2.0.1.Final-plugin.tar.gz
> tar -xzf /kafka-3.3.1-src/libs/debezium-connector-sqlserver
> plugin.path=/kafka-3.3.1-src/libs
jar files should placed under “/kafka-3.3.1-src/libs/”
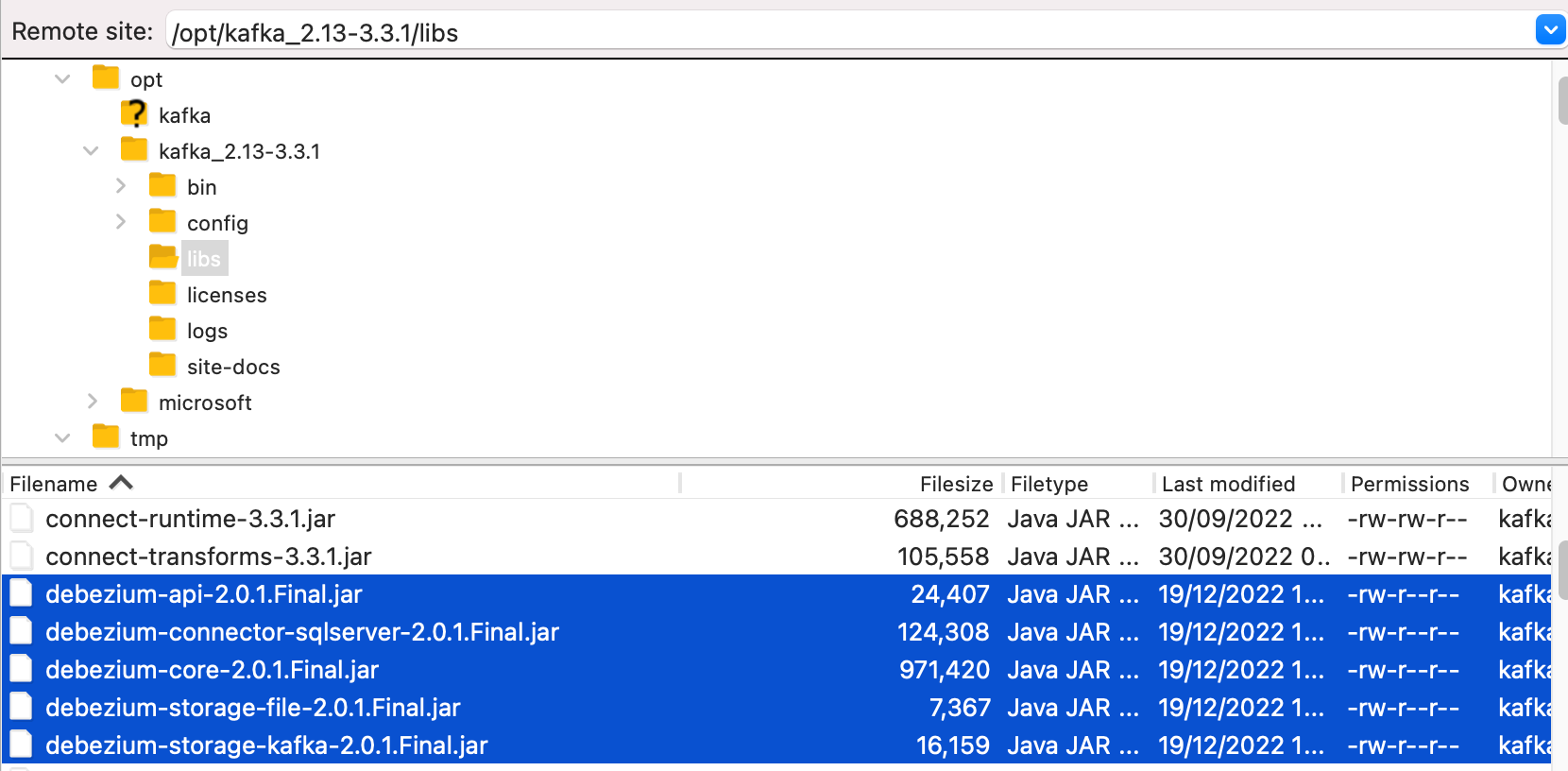
Debezium currently supports following list of connectors:
Note: An incubating connector is one that has been released for preview purposes and is subject to changes that may not always be backward compatible.
Azure SQL Database
As we want to set up CDC and Debezium to stream data from SQL Server, we would need SQL Server installed somewhere. For this article we have used Azure SQL Database with Wide World Importers as sample database.
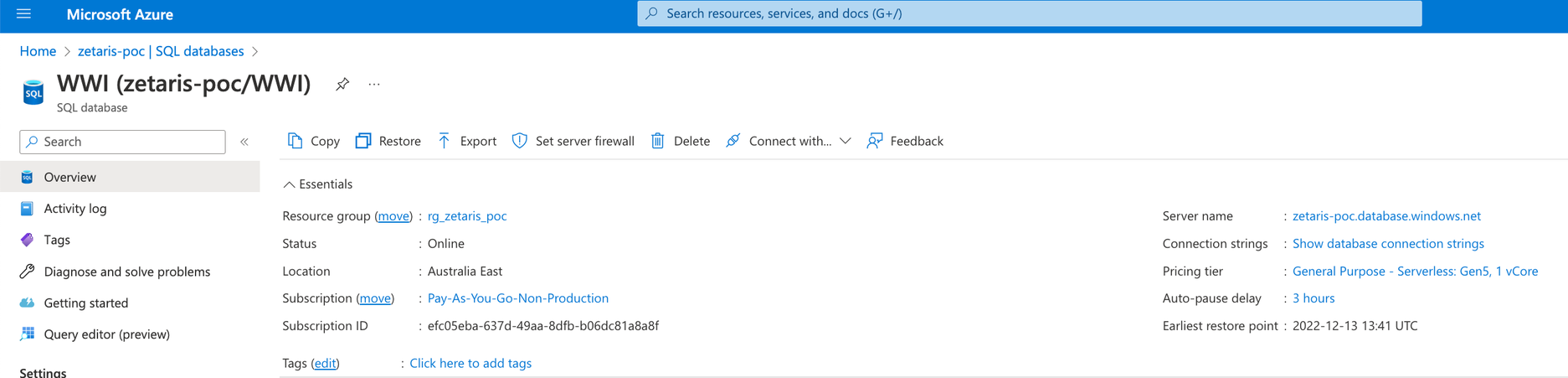
CDC on Azure SQL databases available for higher than the S3 (Standard) tier or vCore equivalent
Steps to configure SQL Server for CDC:
- Create Debezium User
-- Create user used in the sample
CREATE USER [debezium-wwi] WITH PASSWORD = 'Abcd1234!'
GO
-- Make sure user has db_owner permissions
ALTER ROLE [db_owner] ADD MEMBER [debezium-wwi]
GO -
Enable CDC, In this sample only two tables are monitored:
-
Sales.Orders
-
Warehouse.StockItems
-- Enable CDC on database
EXEC sys.sp_cdc_enable_db
GO
-- Enable CDC on selected tables
EXEC sys.sp_cdc_enable_table N'Sales', N'Orders', @role_name=null, @supports_net_changes=0
EXEC sys.sp_cdc_enable_table N'Warehouse', N'StockItems', @role_name=null, @supports_net_changes=0
GO
-- Verify the CDC has been enabled for the selected tables
EXEC sys.sp_cdc_help_change_data_capture
GO -
Configure Debezium to capture CDC events and publish them to the Kafka topic(s)
Step 1 : Start A Zookeeper
Kafka provides a CLI tool to start Zookeeper which is available in bin directory. Run the following command from Kafka folder “/kafka-3.3.1-src/”:
Step 2 : Start A Kafka Server
Run the following command:
Before starting Kafka, make sure to update “advertised.listeners“ with your public ip address in “config/server.properties“ file
Step 3 : Configure Kafka Connect
Create a file “connect-debezium-source-mssql.properties” for Kafka Connect worker properties and place under “/kafka-3.3.1-src/config/“ directory.
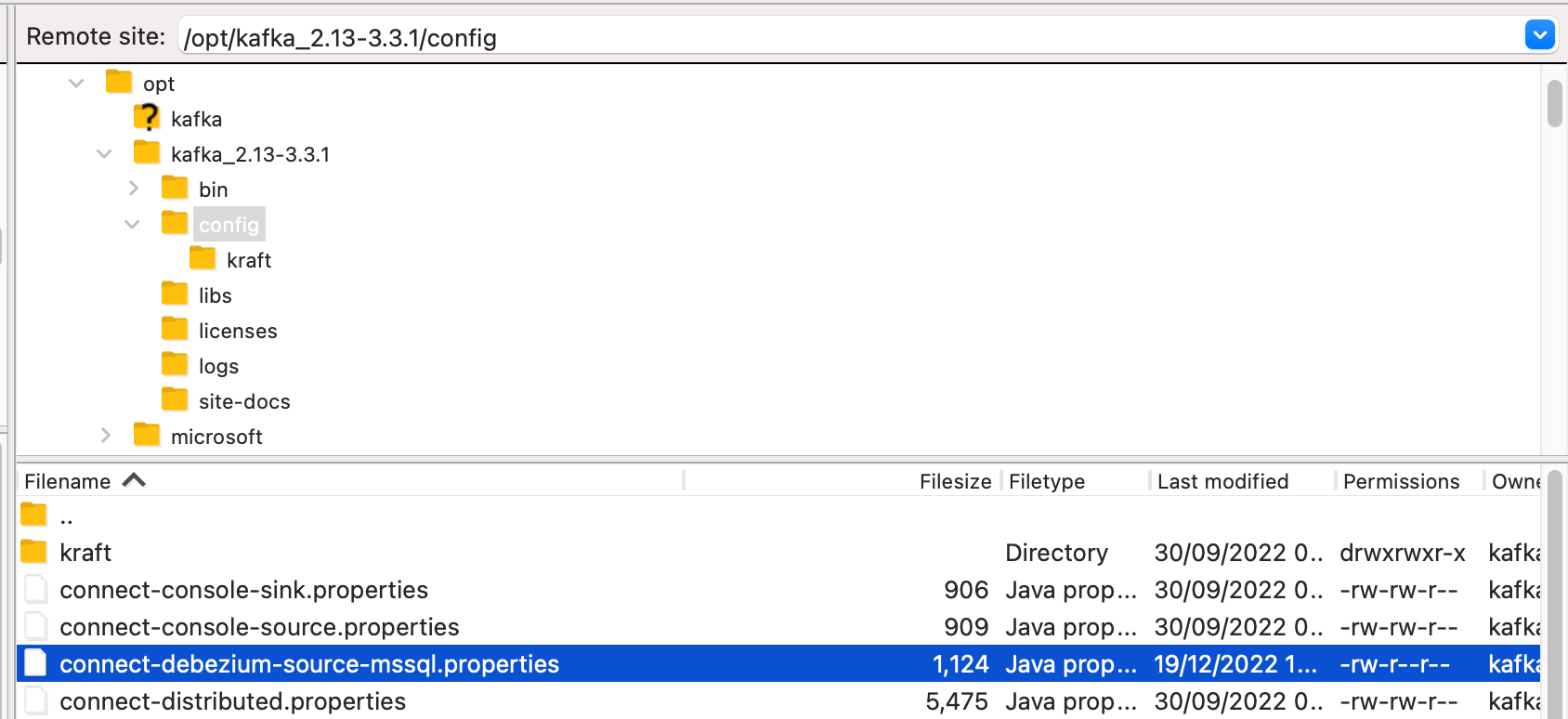
Refer
Debezium connector for SQL Server :: Debezium Documentation document for more information on required/advanced properties for SQL Server connector.
To start streaming by starting the Kafka connect, run the following command.
bin/connect-standalone.sh config/connect-standalone.properties config/connect-debezium-source-mssql.properties
Now check that the connector is established & running successfully using following commands.

curl -X GET http://localhost:8083/connectors/sql-server-connection-wwi/status | jq
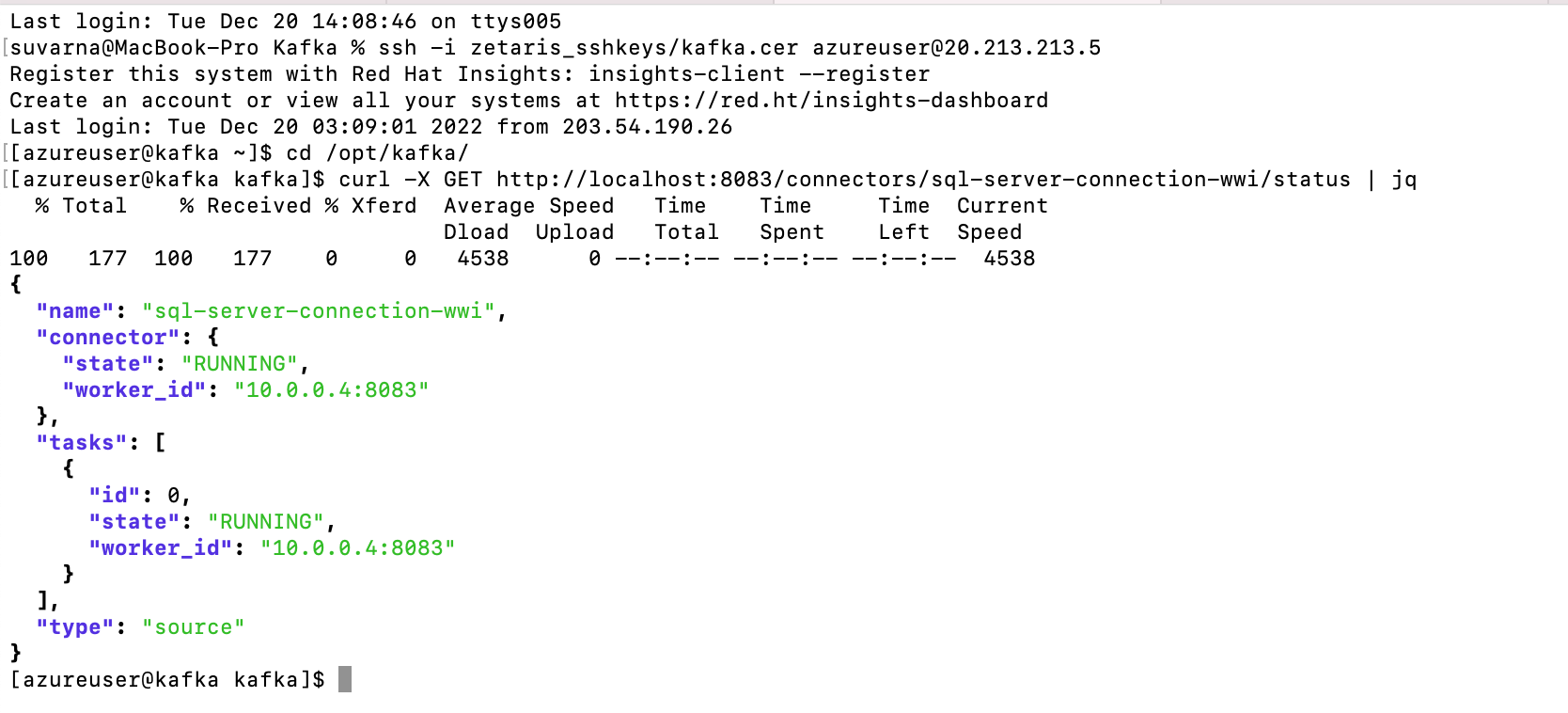
From above screenshot, If you see any errors in under tasks section there must be some issue in SQL Server connection properties, check the logs and make sure we have configured right values in “config/connect-debezium-source-mssql.properties“
Step 4 : Monitor Kafka Logs For Change Data
-
Check list of topics generated
bin/kafka-topics.sh --list --bootstrap-server 20.213.213.5:9092
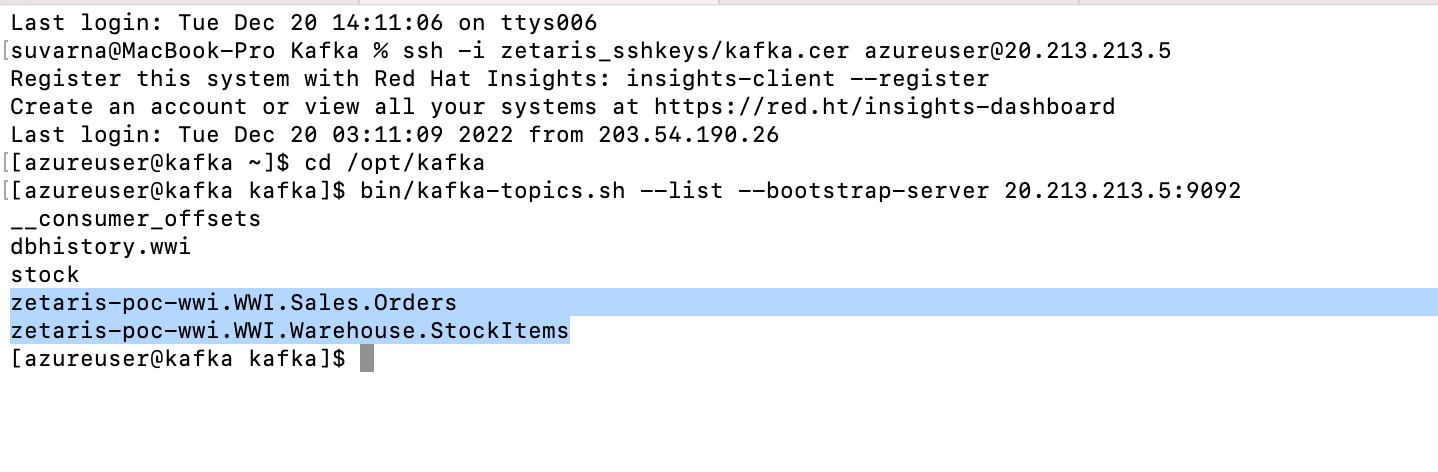
-
Make some simple changes on SQL Database
UPDATE [Sales].[Orders] SET PickedByPersonID = 2 WHERE OrderID=2
UPDATE [Warehouse].[StockItems] SET ColorID=7 WHERE StockItemID=21
UPDATE [Warehouse].[StockItems] SET ColorID=8 WHERE StockItemID=22
-
Run following command specific to Orders & StockItem topics to view changed data
bin/kafka-console-consumer.sh --bootstrap-server 20.213.213.5:9092 --topic zetaris-poc-wwi.WWI.Sales.Orders


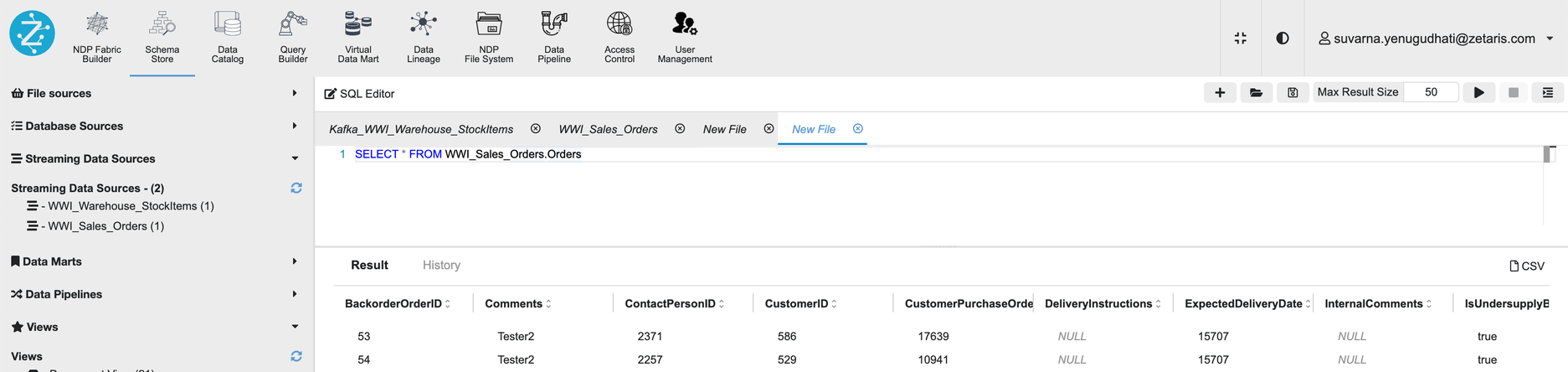
Establishing connection to CDC Data through Zetaris Lightning
In order to connect CDC data on Kafka server, follow the instruction from the article Streaming Data Source - specifically Apache Kafka to establish connection on Zetaris Platform.
Video
References
Debezium connector for SQL Server :: Debezium Documentation