Introduction
Leveraging a streaming data source provides the ability to:
- Collect data from any application
- Ingest the streaming data and perform additional processing such as persisting the contents to a database or file format (e.g. Parquet, JSON).
Zetaris supports Apache Kafka streaming which consists of the following logical components:
- Topic - messages belong to a particular category called a topic
- Producer - publish messages to one or more Kafka topics.
- Consumer - subscribe to one or more topics and consume published messages
Architecture
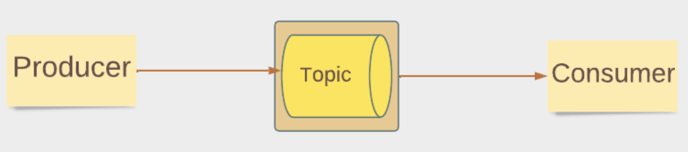
In this architecture, Zetaris plays the role of the Consumer, with topic definitions and publishing of messages performed outside of Zetaris.
The integration point between Zetaris and Kafka is the topic.
On the Producer side, we will leverage the Kafka producer console to publish messages.
For our scenario, we will ingest streaming data from and perform additional processing such as persisting the contents to a database or file format (e.g. Parquet, JSON).
Use Case
For our scenario, we have a Stock Ticker stream that publishes updates on technology stock equities. As the consumer, Zetaris will ingest streaming data and persist the contents to a Parquet file format to the file system.
Kafka Steps
- Ensure Kafka is running
- Create a topic, in our example the topic is named stock.
- Ensure your firewall permits connections to your kafka bootstrap port (e.g. 9092).
Connect to a Streaming Data Source
- Click on NDB Fabric Builder widget.

- Click
 next to Streaming Data Sources.
next to Streaming Data Sources.
- Specify the following values:
Data Source Name Stock_Ticker Input Format JSON Input Source Kafka kafka.bootstrap.servers your kafka boostrap server and port kafka.topic stock kafka.security.protocol PLAIN kafka.sasl.mechanism PLAIN
For Input Sample enter the following JSON payload:{
"symbol" : "AAPL",
"name": "Apple",
"price": 150.12,
"previous_close" : 148.01,
"open" : 148.13,
"bid" : 150.26,
"ask" : 150.27,
"volume" : 50304716,
"avg_volume": 89767359
} - Your completed dialogue should look like the following:
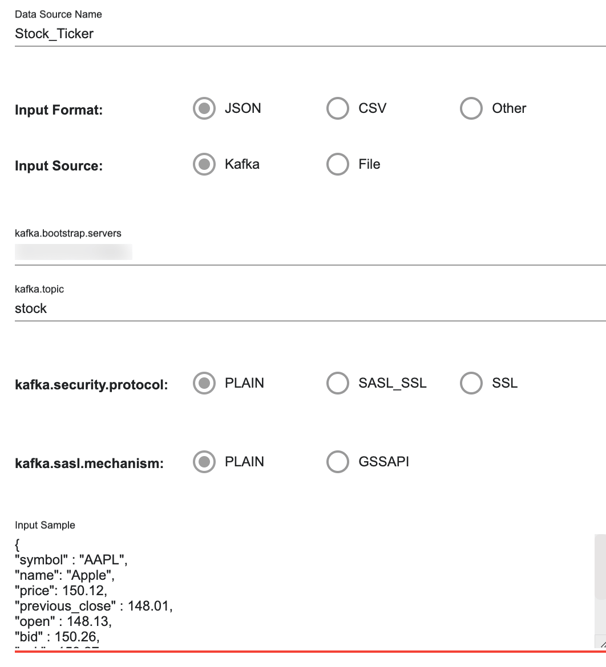
Click Create. - Your streaming data source should now appear.

- Click next to your streaming data source to add an aggregation table.

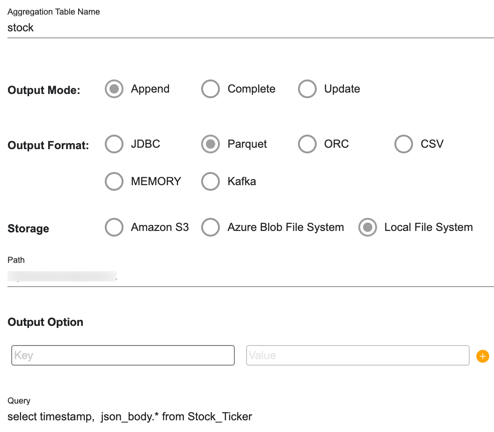
- Specify the following values:
Aggregate Table Name stock Output Mode Append Output Format Parquet Storage Local File System File Path File path accessible to Zetaris For the Query enter the following:
select timestamp, json_body.* from Stock_Ticker
- Your completed dialogue should look like the following:
Click Create. - You should now see your newly created aggregate table.

- Click the aggregated table to expand.

- You should see a data structure that corresponds to the query we entered.

- Click preview next to stock to view the contents of the table.
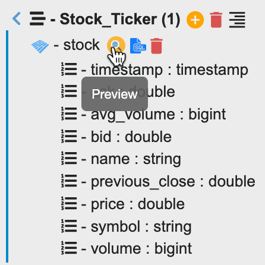
Note - there will not be any contents as messages are yet to be published to the topic.
Publish messages
- Switch to your KAFKA_HOME/bin directory
- Start the topic producer
./kafka-console-producer.sh --broker-list localhost:9092 --topic stock
- Enter the following JSON payload and hit Enter to send the message.
{"symbol" :"AAPL", "name":"Apple","price":150.12,"previous_close" :148.01,"open":148.13,"bid" :150.26,"ask":150.27,"volume":50304716,"avg_volume":89767359} - Repeat the above exercise the the following JSON payload and hit Enter to send the message:
{"symbol":"SPOT","name":"Spotify","price":75.25,"previous_close":74.12,"open":72.97,"bid" :74.98,"ask":75.25,"volume":1564035,"avg_volume":1847590}
View Messages
- Switch back to your Zetaris GUI to view messages consumed.
- Click preview next to stock to view the contents of the table.
You should see the following 2 messages in the result, corresponding to the messages we published from Kafka in the previous step