In addition to Spark default tuning, what can be done in Zetaris to aid in optimization and performance tuning of Spark Cluster resources
Spark configuration Parameters
Pushing Predicate Aggregation to the Source
Cost based and Rules Based Optimization
First, get an understanding of Zetaris Deployment Fundamentals.
Spark configuration Parameters
Running MPP queries splits the query into multiple stages, which can all run in parallel. Thus each table in a join could be run in its own parallel stream. The proviso in this case is that there are enough nodes in the cluster to run each section / stage in parallel. Spark’s adaptive query optimization is able to dynamically detect skewed partitions and allocate CPU resources to the relevant partition, on the fly.
Tweaking the maximum number of tasks for a shuffle or join can result in improved performance. This is done by adjusting the configuration parameter spark.sql.shuffle.partitions. This is set to 200 by default, but adjusting it to match the number of CPU cores across the cluster has been shown to provide significant performance enhancements.
Tweak the metadata cache TTL [default 1000]. The default setting of 1000 for the spark config parameter spark.sql.metadataCacheTTLSeconds means that cached execution plans are never expired. An alternate setting of 3600 (seconds) will ensure that cached plans are flushed after 1 hour.
FAIR Scheduler
By default, a FIFO scheduler is used, meaning that any incoming queries in the job queue will be executed when there are available CPU resources. This means that for the end user, total elapsed time will include queueing time (which is variable) and could result in lengthy delays in responses.
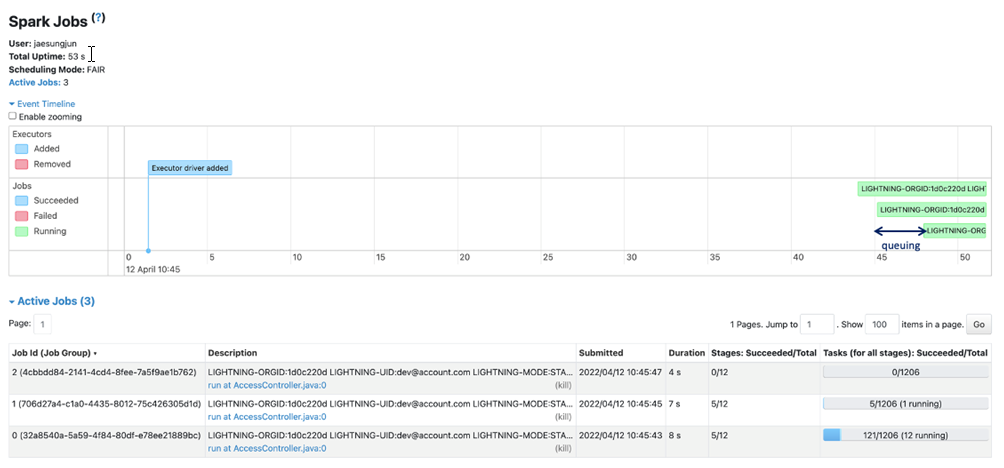
The graphic above shows how the last job was queued but only executed once the CPU resource was freed up from other previously running jobs.
Using Zetaris FAIR scheduler allows a time-slicing mechanism to increase the number of concurrent jobs.
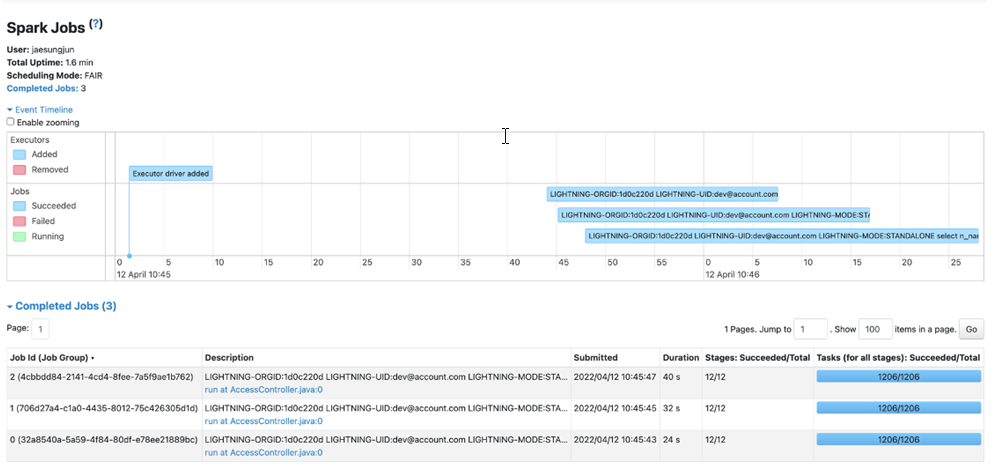
The screenshot above shows that the third job had started to execute before the physical completion of the other current jobs in the queue. Queueing time is reduced and overall response / elapsed time is reduced to provide improvised performance for the end user.
With the release of Spark 3.3, the Volcano scheduler will be supported for Kubernetes based implementations. This allows fine-grained resource management leading to improved performance of large-scale data analysis. This will also eliminate node resource deadlock.
Pushing Predicates aggregation to the Source
IF a join compares different data types, type casting is required for the join to succeed. When this type casting is done, the predicates of the join are able to be pushed down to the source.
Aggregation (MIN, MAX, AVG, SUM, COUNT together with GROUP BY) can be pushed down to the source. Spark generally scans all data sources and aggregates by shuffling the data. Zetaris automatically pushes the aggregation to the source (which generally does it a lot faster) and avoids the shuffling operations for aggregation in Spark.
Rules based and cost based optimization
Rules based optimization takes place in Zetaris. A typical example is column pruning. If an inner query contains select * but the outer query has explicitly stated select columnA, columnB, then not all the column are required, therefore resulting in less data needing to be retrieved from source and consequently speeding up the query runtime.
Cost based optimizations relies on statistics and using these statistics (which are stored internally in Zetaris as part of the metastore) the most optimal execution path is chosen that incorporates cardinality, join type and column distribution.