Zetaris' architecture utilises Apache Spark's framework as its query engine. So to understand how Zetaris is operating and to manage it effectively, it is helpful to understand the fundamental concepts of its cluster, being Apache Spark.
What is Apache Spark?
Spark is a distributed cluster-computing software framework.
To achieve distributed computing requires resource and task management over a cluster of machines. Resource management involves acquiring the available machines for the current task, while task management involves coordinating the code and data across the cluster.
A Spark application consists of a driver program and executes parallel computing on a cluster. To start a Spark application, the driver program that runs on a host machine will initiate a SparkContext object. This SparkContext object communicates with a Cluster Manager, which can be either Spark’s own standalone cluster manager, YARN, or Kubernetes, to acquire resources for this application. Then, the SparkContext object sends application code and tasks to the worker nodes.
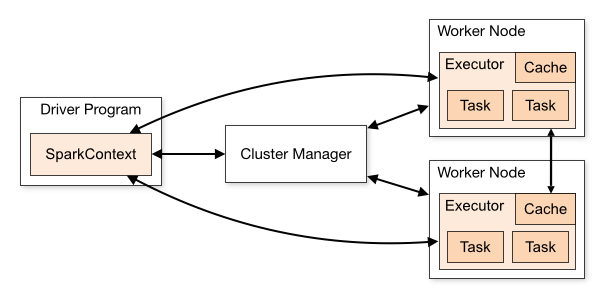
Modern day deployments tend to opt for Kubernetes, as it generally offers better scalability, dependency management and resource management. Zetaris would generally recommend Kubernetes or YARN as preferred cluster managers.
For one application, a worker node can have multiple executors, depending on the number of CPUs available on this worker node. During the computation for an application, each executor, using Resilient Distributed Datasets (RDD), keeps data in memory or disk storage and runs tasks. In this way, executors are isolated from each other, and the tasks for the same application run in parallel and has a high degree of fault tolerance.
Then, to query across your Zetaris deployment, we using the Spark SQL interfacing language.
Cluster Managers
YARN
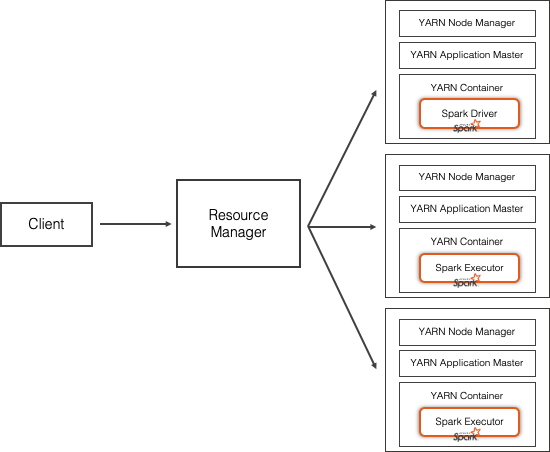
YARN stands for Yet Another Resource Negotiator. Originally built to relieve bottle necks and take control of Resource Management and Job Scheduling for the Hadoop Distributed File System (HDFS).
YARN is a middle layer in between the applications and HDFS. It enables multiple applications to run simultaneously on the same cluster of machines by acquiring resources based on the need of each application. YARN has two main components:
-
A Resource Manager which controls resource allocation over the entire cluster
-
Multiple Application Managers that run on each node, managing each application.
When running applications, the Application master sends the heartbeat and job progress info to the Resource Manager, as depicted below. This makes it possible for the calling client to check the application status from the Resource Manager, using YARN’s web UI that displays the resource and job status of the various applications being run on the nodes.
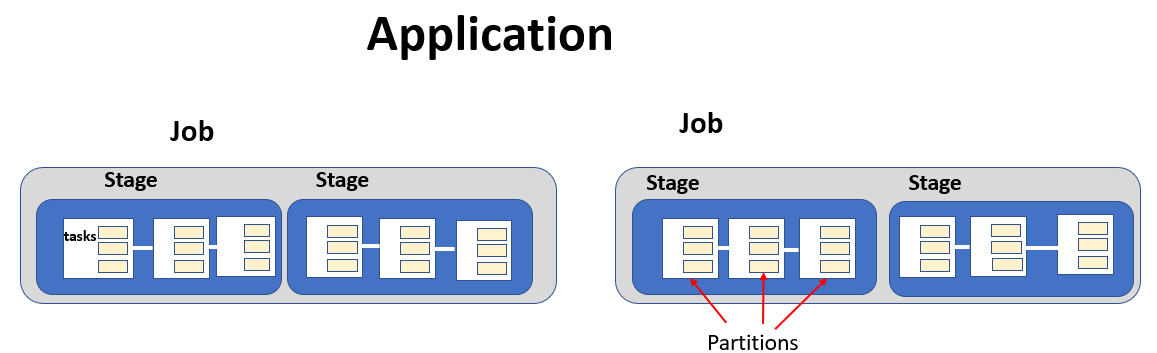
Application, Job, Stage, Tasks
In YARN, spark task management is monitored on four different levels.
An Application consists of a driver program executed on the cluster. The client submits an application (e.g. count the number of products per store)
The application involves multiple jobs which run in sequence. Jobs are defined by action operations. An action operation will cause the separation of jobs.
A job involves multiple stages which run in sequence. A stage is generated upon wide dependency transformations
A stage involves multiple tasks that run in parallel. The number of tasks corresponds to the number of parallel concurrent executors (defined by partitions)
To get an idea of potential performance bottlenecks, we need to look at the number of different tasks.
More information on YARN and how it fits into the Spark context can be found here:
Kubernetes
Kubernetes is becoming the more popular choice for Spark deployments, for its effectiveness in automating, scaling and monitoring of container-based application infrastructure. Further its interoperability and agnostic characteristics, allows for efficient and smoother DevOps cycles.
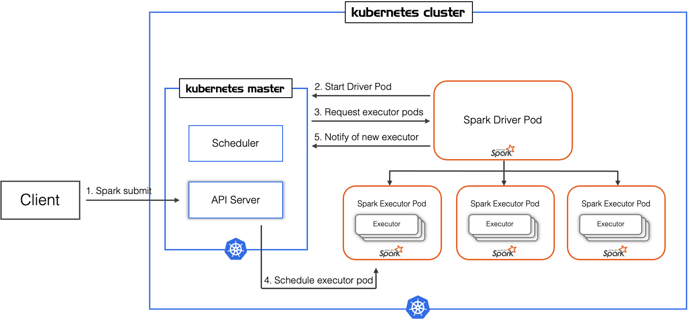
More information on Kubernetes and how it fits into the Spark context can be found here:
To understand the steps for how to deploy Zetaris in a Kubernetes environment, please use the following guide:
Components of a Spark Cluster
Resilient Distributed Datasets (RDDS)
RDD is a core abstraction in Spark and it enables partition of large data into smaller data that fits each machine, so that computation can be done in parallel on multiple machines. Moreover, RDDs automatically recover from node failures to ensure the storage resilience.
For more information, please visit the Apache Spark documentation, Resilient Distributed Datasets (RDDs).
RDDs are immutable (WORM). This means that Spark supports complex operations by creating series of RDDs, known as lineage. This also enables easy recovery for failed RDD from the dependency chain.
RDD supports 2 kinds of operations:
· Action
· Transformation
Transformations are evaluated in a lazy way, meaning that transformation operations will not be performed without some action triggering the calculation. Transformation includes filters, joins, aggregation.
Actions include collect, count and save operations.
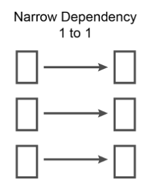
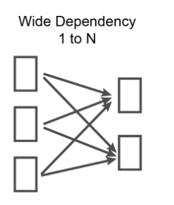
Narrow vs Wide dependencies
Spark computations are performed by multiple executors in the cluster, where each executor executes a portion of the data in a partition. However in RDD lineage, the results from one partition might not land up in the same partition.
| Narrow Transformation | Wide Transformation |
| A parent partition corresponds to a child partitio | A parent partition corresponds with multiple child partitions |
|
Consumes more network bandwidth |
|
| Faster | Slower, as it involves larger scale shuffling of data from different executors |
 |
 |
Spark SQL
Spark SQL allows one to work with structured data, as it works with DataSets and DataFrames. Using Spark SQL, one can issue declarative commands (as opposed to low-level API). Spark Catalyst optimizes the performance.
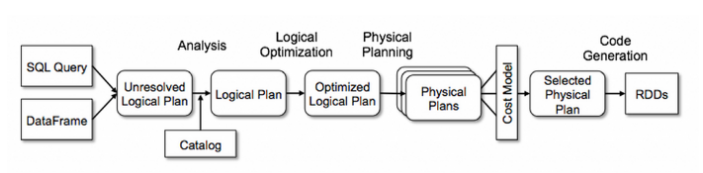
Spark SQL is the core module in Spark and its emphasis is on calculation and is usually used in large scale ETA and pipeline.
Driver Node
There is minimal CPU needed on the driver node as it only runs the driver program. Driver nodes generally require more memory. Why ? Because when collect operations involve pulling results from executor nodes, if there is insufficient memory, an OOM situation is likely to occur.
Executor Node
CPU cores determine the level of parallelism on the executor. More cores means higher level of parallelism. Executor node memory is paramount, as it enables in-memory faster computing. Executor memory is divided into 4 parts: reserve, user, storage and execution memory.
|
Storage memory |
Execution memory |
User memory |
Reserved memory |
|
Used for caching |
Shuffling calculations |
Stores data structures and metadata |
Runs the executor |
|
Dynamic sharing of memory structures, can overflow to disk if needed |
Do not support spilling to disk. OOM potential |
||
Storage memory and Execution memory share the memory is a dynamic way, but this sharing favours execution memory. If there is free space in one of the memories, the other can borrow from it. However, if storage memory occupies more space, execution memory can claim back space when it is needed and force storage memory to overflow (spill) onto disk.
If a dataframe is cached or persisted, the data will be stored in storage memory. The YARN web UI can monitor and display the persisted data in the storage tab.
User memory stores the data structures and metadata required for RDD transformation