Pre-Requisites
For this demo we have used following components to generate delta files on Azure Blobs.
-
Azure SQL Database - As a Data Source
-
Azure Data Lake Storage Gen2 - As a Storage
-
Azure Data Bricks - As a ETL Tool
-
Azure Key Vault - To Store Secrets
Please note that requested access to
GITHUB links will be required in order access files.
Azure SQL Database
This is optional, skip this step if you already have delta data in your storage
You can also use any other data source as required. However make sure to have changed records (New/Updated/Deleted) in source in order to populate delta lakes.
-
Setup an Azure SQL Database: For this article we used server less SQL Database.
-
SQL Scripts:
-
Sample scripts provide here on GitHub
-
Connect to new Azure SQL Database created and set create & load base data to the TestDeltaLake table using the scripts “01_Create_TestDeltaLake_Table.sql“ in the repo.
-
To run scripts follow the instructions provided in Databricks Notebook.
-
Azure Storage
-
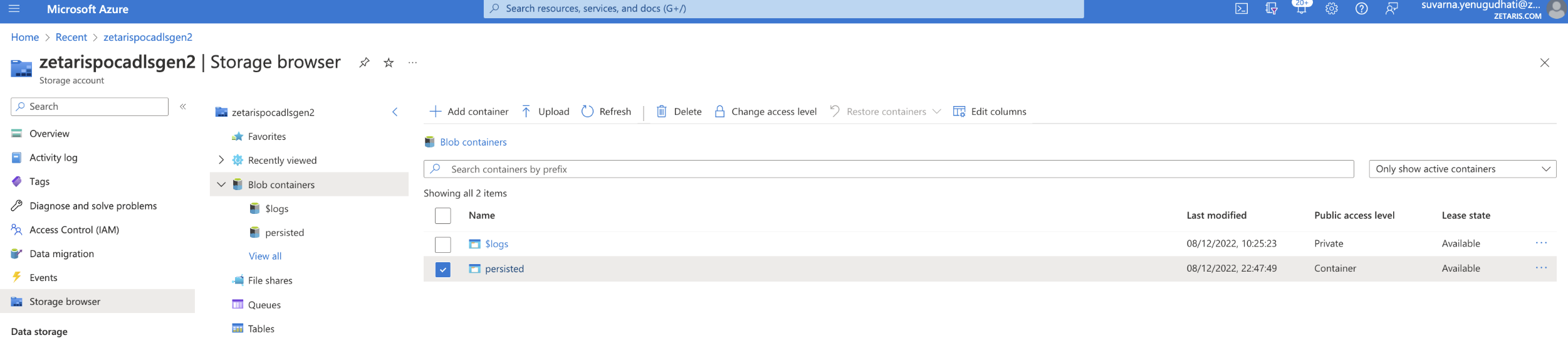
Create a Data Lake Storage Gen 2: ADLSgen2 will be the Data Lake storage on top of which the Delta Lake will be created. Refer this Delta Storage article for other storage types i.e., Blob & ADLS Gen1.
Create a Data Lake Storage Gen2 Container/Zones: Once your Data Lake Gen2 is created, also create the appropriate containers/Zones.
-
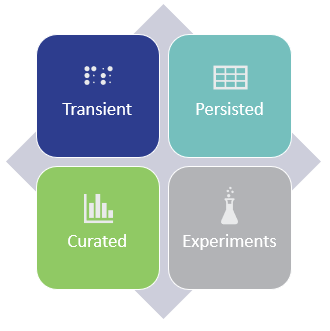
Best practice, is breaking the Data Lake up into four zones
-
Transient – In this zone, we rest data temporarily as it moves from the source to the persisted area, think staging. Data in this zone is periodically removed, based on the file time-to-live.
-
Persisted – Data is kept indefinitely in its raw format and is immutable to change. This zone is often referred to as persisted staging. It provides a historical representation of raw data at any given point in time.
-
Curated – Data in this zone has been transformed, enriched and/or aggregated to meet specific requirements.
-
Experiments – This is a dedicated zone used by analysts and data scientists for “experiments”.
-
-
For this article we have created “persisted“ container to store a sample source parquet file and also used for Delta Inserts, Updates and Deletes from source.
Azure Key Vault
This is optional, skip this step if you already have delta data in your storage
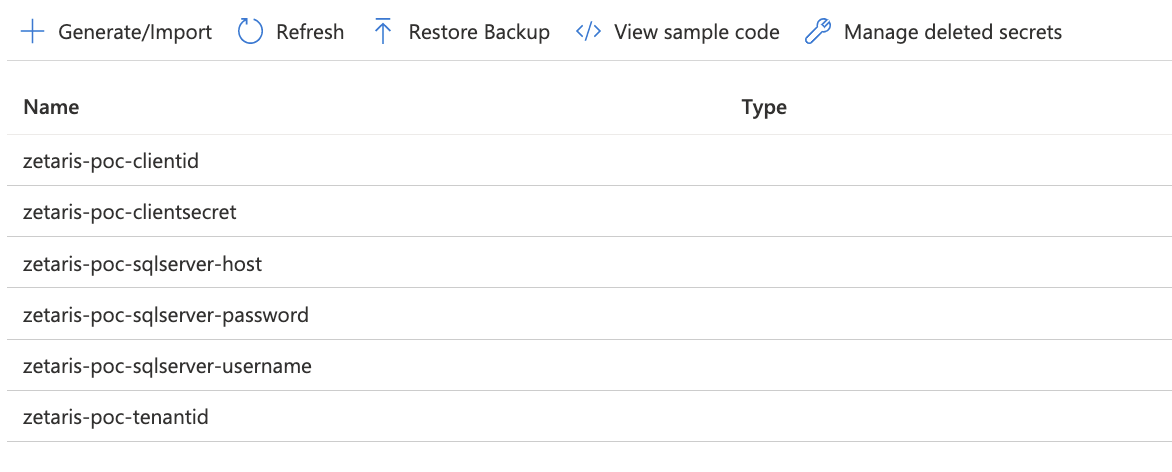
Azure Key Vault will be used to store SQL Database and Azure Service Principle secrets. Setup Key Vault account and create following secrets to use in data bricks notebook variables.
Azure Data Bricks
This is optional, skip this step if you already have delta data in your storage
Azure Data Bricks will be used to perform the ELT orchestrations and also to create and manage the Delta Lakes.
- Setup cluster in Databricks. Configured “Standard_DS3_v2“ cluster for trial purposes.

- Setup notebook for Delta Lakes. The following is a sample notebook created to load data to ADLS Delta Lakes - Import this sample notebook into workspace: pocDeltaLakeADLS.dbc
-
Create Secret Scope & Update variables
-
Update variable with required values under “Set notebook variables"
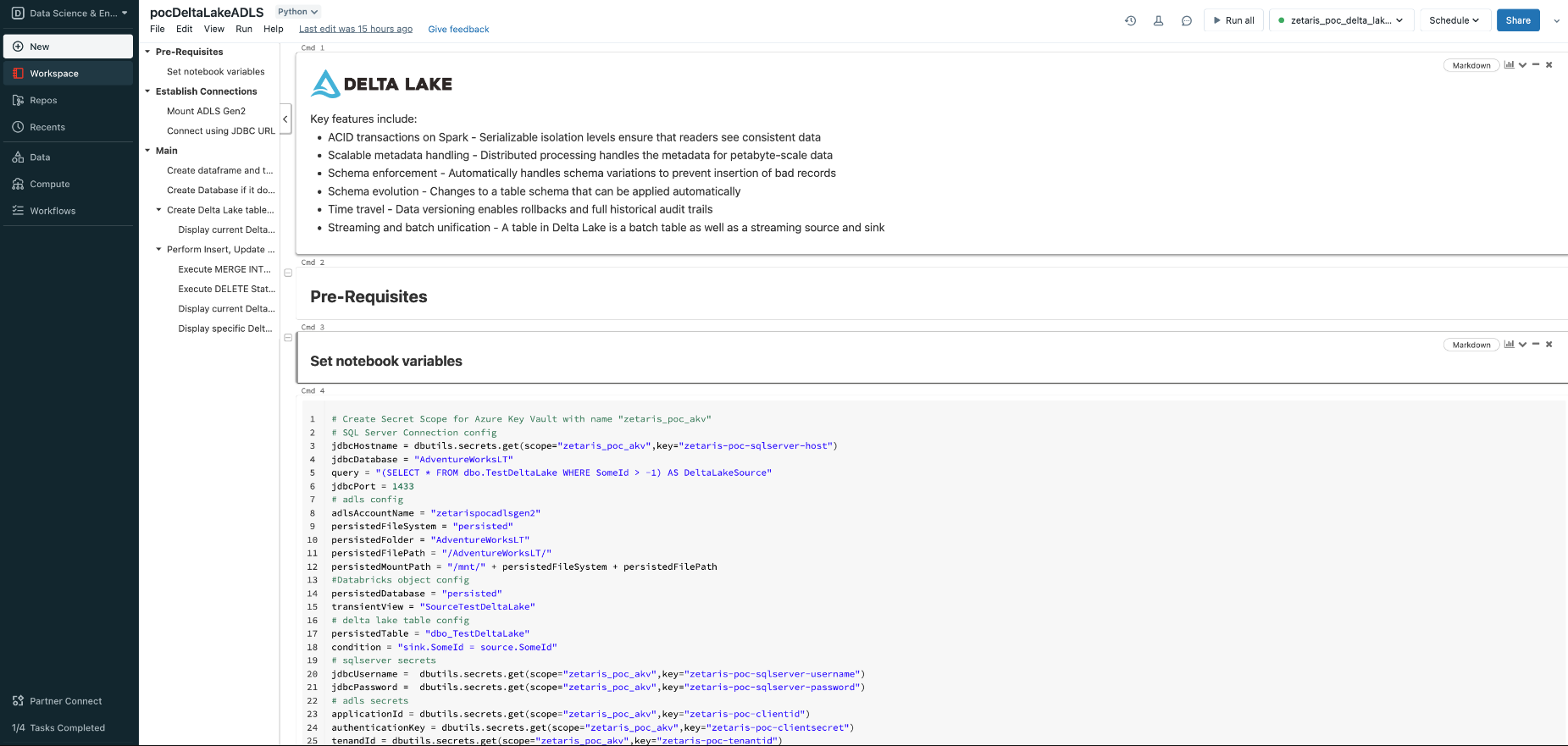
- Attach notebook with the cluster created in Step 1. Follow the notebook instructions to run commands.
-
Make sure to run last SQL Script “03_Change_Baseline_Data.sql” before the instruction “Perform Insert, Update and Delete actions if required”.
- Once the notebook is completed running, looking at the ADLS2 “persisted“ container, we see that a delta_log folder along with 3 snappy compressed parquet files have been created.
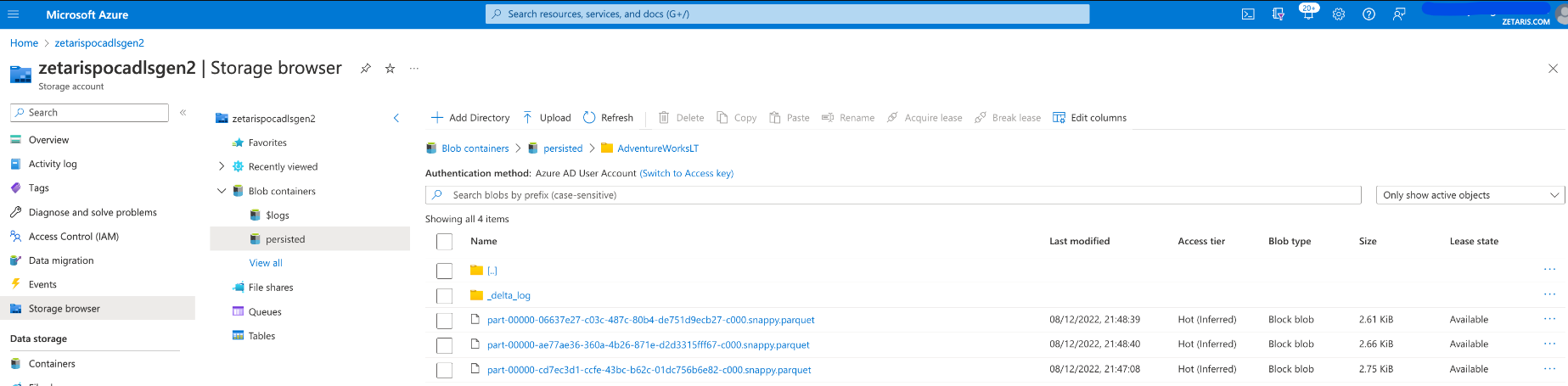
-
- Explore delta logs. The main commit info files are generated and stored in the Insert, Update, and Delete JSON commit files. Additionally, CRC (technique for checking data integrity) files are created.
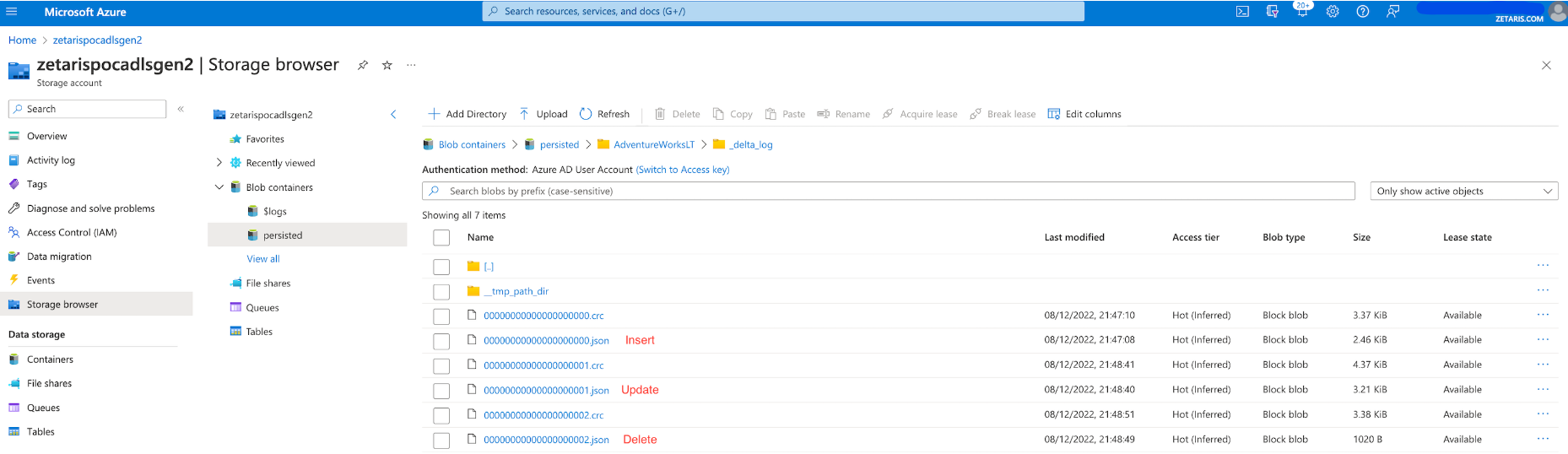
Establishing connection to Delta Lakes
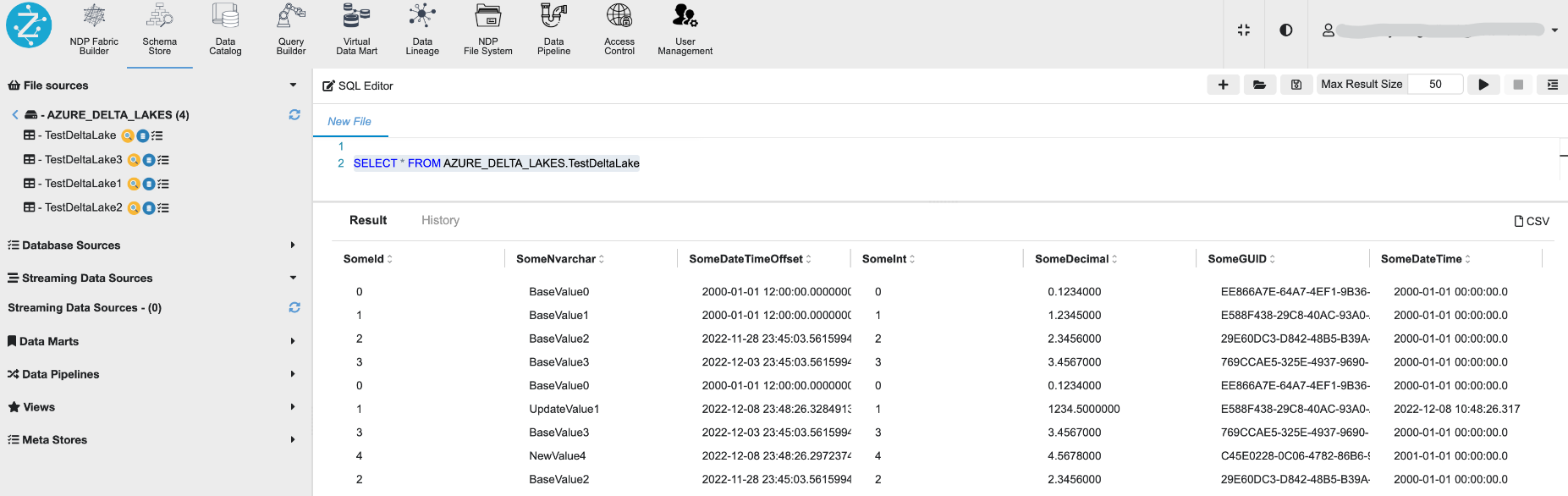
As Delta Lake data is stored in Azure blobs in parquet format, so we can useAzure Blob file source connection on Zetaris Platform.
Make sure your Azure Blob Container has “Public Access Level“