When deploying a clustered Zetaris deployment, whether it be on-premises or in the cloud, your Zetaris cluster will have differing fault tolerance behaviours based on the node or executor that has been compromised.
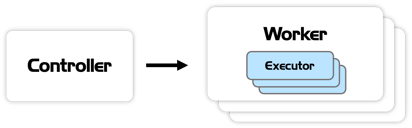
Zetaris cluster
In your base Zetaris cluster you will have:
Controller:
- Only one active/primary controller per cluster
- Coordinates, at query run-time, the allocation of jobs across executors
Worker:
- Indefinite amount
- Houses the compute resources that executors are able to utilise
Executor:
- Can deploy multiple executors per worker. Usually depends on the number of cores/threads accessible in the worker node.
- Processes jobs given by the controller
- By default, 1 executor will run 1 thread, though this can be modified
- Resilient Distributed Datasets (RDD)
Fault Tolerance
In the event of a failure at the worker node:
- In-memory data will be lost, so any executors in computation, will fail.
- However, because lineage of partitions is logged, we recreate those lost datasets in the failed worker node, across to an active node.
- The diagram below shows a classic query execution plan, whereby each partition is traced back to its origin, without have to write each partition to disk.
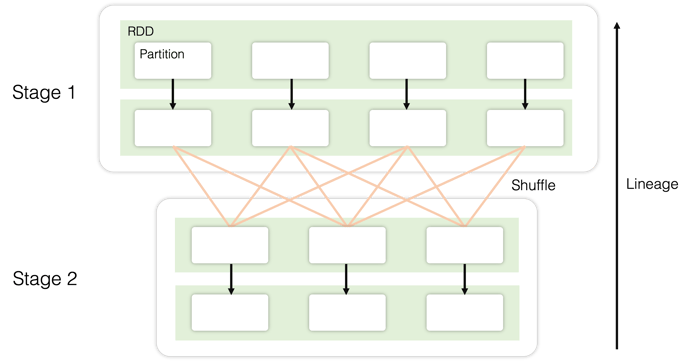
In the event of a failure at the controller node:
- Cluster wide failure, as the controller is the central point of all query executions. To prevent this, we would advise configuring for High Availability.