Purpose of a Data Vault
To encourage flexibility by handling changes to source systems or target business requirements.
To increase usability by business users (a Data Vault is modelled after the business domain).
To improve performance:
- Data Vault supports near-real-time loads as well as batch loads;
- Terabytes to petabytes of information (Big Data);
- Decoupling of key distribution enables a very high degree of parallelism due to a reduction of ETL (Extract, Transform, and Load) dependencies.
To establish historical traceability.
To support isolated, flexible, and incremental development (organic growth):
-
Dynamic model can be incrementally built, easily extended;
-
No re-work is required when adding information to the core data warehouse model;
-
Supports business rule changes with ease.
Best Practices for a Successful Data Vault
- Each source entity transforms into a Hub.
- All attributes from source must be brought into the Raw Vault as is.
- The Hub key must be a unique identifier.
- All hubs must contain a BKCC (Business Key Collision Control) which can be defaulted to country code (e.g., ‘AU’).
- All components should be tagged with dss_record_source and dss_load_date (datetime2) as mandatory fields. (Note: business dates should not be mapped into these fields).
- Look at what fields will be tokenised/masked/encrypted to enable privacy or split satellites.
- Split files according to rate of change: fast vs. slow.
- Real time data does not need a load/landing area.
- Indexes need to be created on a combination of hash key and dss_load_date.
- Business Vaults can involve Raw Vault Hubs with business-rule generated satellites.
Naming Conventions
General Rules
- No spaces in entity names.
- All component names must be in lower case.
- Replace all special characters with a space.
- Replace meaningful special characters like '%' with their corresponding word (e.g., percent).
- Names of all components will be in lower case with an underscore separating split names.
Load table = load_<business area> e.g.: load_customer
Landing table = landing_<business area> e.g.: landing_customer
Stage table = stage_<business area> e.g.: stage_customer
Raw Vault Hub = h_<business area>
Raw Vault Link =l_<business area>
Raw Vault Satellite =s_<business area>
Raw Vault HashKey =hk_<business area>
Raw Vault HashDiff =hd_<business area>
Business Key Collision Code =bkcc_<business area>
Pit = p_<business area>
Bridge =b_<business area>
Business Vault Hub = h_<business area>_bv
Business Vault Link =l_<business area>_bv
Business Vault Satellite =s_<business area>_bv
Business Vault HashKey =hk_<business area>_bv
Business Vault HashDiff =hd_<business area>_bv
Reference Vault Hub = h_<business area>_ref
Reference Vault Satellite =s_<business area>_ref
Reference Vault HashKey =hk_<business area>_ref
Reference Vault HashDiff =hd_<business area>_ref
Implementation of a Data Vault Model in Zetaris
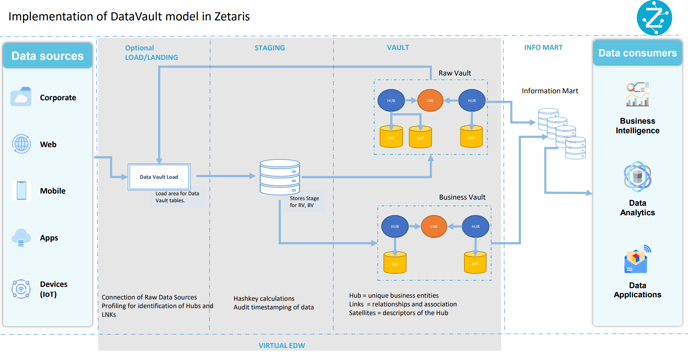
Step1: Data Source Registration and Profiling.
This is the process of acquiring source metadata and the mappings associated with the business requirements. In this step, it is beneficial to identify the business keys, primary keys (if available), and the metadata that describes the source data. Data profiling assists with understanding how the business keys link the data and provide foresight into any data quality issues that might arise from the violation of the core principles of uniqueness, completeness, and consistency.
Step 2: Design Landing and Staging Areas.
Once we have gathered all this information, we need to design the virtual/physical landing and staging areas. The primary reason to have a landing layer for batch processes is to pull all the source data into this layer and reduce work loads on source systems.
Note that landing tables need to be used only in cases where there is evidence of transformation due to hard rules from source to RawVault. This is particularly relevant for batches or micro-batches, but not very relevant if data can be delivered in real time or using replication or imaging from source.
Step 3: Hashkey generation.
Keeping all data readily available, we go for hashkey generation. The below additional columns are created and added on to the source data.
dss_record_source Should outline the source of data. It is best to use system names keeping in mind that lineage requirements might need this to be captured clearly.
dss_load_date Imprint the current system date so as to maintain an audit history of each record.
bkcc Business Key Collision Code is an attribute used to avoid any duplication of the business key when the same business keys are available from different source systems. This might lead to duplication of the business key
hk_h Hashkey generation using md5 algorithm as Zetaris currently does not support sha256. The hashkey must be generated on a combination of the bkcc and the business key.
Sample code: <md5(concat(bkcc,cast(o_orderkey as varchar(255))))>
hd_s The hashdiff key generation happens only in satellites. This key captures all fields that have a slowly changing dimension and is defined as an md5 algorithm.
Sample code: <md5(concat(o_orderstatus,o_orderpriority,o_clerk,o_comment, cast(o_shippriority as varchar(255))))>
The purpose of using Hashkeys
When we use a hashkey, we need to remember that it is not an encryption key. Although the hashed data may look encrypted, hashing does not protect the business key and should not be used for security considerations. The hashkey can be considered as a replacement for sequence surrogate keys.
Remember, hashing the business key is done to achieve the following goals:
- Enable heterogeneous platform joins.
- Consistency of performance on joins regardless of volume of data.
- Random even distribution of data sets across MPP environments.
- Parallel loading and independent load processes without sequential load dependencies.
- High-speed queries without the need for lookup caching or hub joining.
- High-performance loading to Satellites and Links without the need for lookup caching or hub joining.
The choice of values for creating a Hashkey
The hashkey is created by converting incoming data into streams of bits and then computing a number or a unique identifier. Every time the algorithm receives the same input, it will compute the same unique identifier.
Points to note:
-
For short business keys, add a fixed-length string to make it long. The longer the business key, the better is the hashing.
-
SHA1 or MD5 can be used as a hashing algorithm but MD5 is the preferred algorithm in Zetaris.
-
Use only relevant columns to build a composite business key.
-
Separators should be valid ASCII characters and all Nulls and spaces need to be handled.
HashDiff
MD5Diff is an md5 hash for all the descriptive data in a Satellite that you wish to compare. Exclude the columns that do not need to be compared for differences. MD5Diff is an added attribute to the Satellites, and generally assists with comparing row values quickly and efficiently. Remember to use the hashdiff naming conventions as mentioned above.
WARNING: A CHANGE (ADD / REMOVAL / ALTERATION) OF FIELDS IN THE SATELLITE WILL FORCE A FULL RE-COMPUTATION OF THE HASH DIFFERENCE VALUE ACROSS ALL HISTORY.
It is for this reason that Hash Differences are *OPTIONAL* in the Data Vault 2.0 standard and should be used with caution. This can be a massive negative impact on Big Data Solutions. It has now been shown to be a best practice to continue with actual column comparisons for this reason.
It also means that Hash Difference is only a best practice when loading 'historically stagnant data sets', or in situations where the size of the data sets is 'not large enough' to cause heart-ache when re-computing.
A sample structure for a Satellite might look like this:
Create Table Sat_Cust
( cust_MD5 char(32) not null,
cust_load_dts datetime not null,
cust_load_end_dts datetime,
cust_rec_src varchar(12) not null,
cust_addr_MD5DIFF char(32) not null,
cust_addr1 varchar(60),
cust_addr2 varchar(60),
cust_city varchar(60),
cust_region varchar(55),
cust_state_province varchar(80),
cust_zip varchar(12) );
The function used to populate the customer address md5diff column would appear as follows: (delimiter =‘:’)
Cust_addr_md5diff = md5(upper(concat (cust_bk,’:’, cust_addr1,’:’,cust_addr2,’:’,cust_city,’:’,cust_region,’:’,cust_state_province,’:’,cust_zip)));
** WARNING: THIS CODE IS PSEUDO-CODE, IT DOES NOT REFLECT THE COMPLETE CODE IMAGE THAT MUST BE UTILISED TO ACHIEVE THE DESIRED RESULT.
Again, these fields must not be null. We convert to upper case so that the MD5 will 'compare' to incoming rows with case insensitivity. If deltas are needed with case sensitivity, then exclude the upper functions .
** IMPORTANT! Remember to ADD the sequence OR the natural primary key field to the HASHDIFF calculation!
This will ensure the most uniqueness of the Hash calculations across multiple similar Satellite rows and greatly reduce the risk of duplicate hashes for different values. If the sequence needs to be part of the Hash Diff it has to be calculated BEFORE calculating the Hash Diff. If, on the other hand, Hash Diff is calculated on the way in to the staging area, then use the NATURAL business keys from the staging data set (this is the recommended method, as this method also works in real time and across heterogeneous ETL loads).
Also note: ALL columns (for both Hash Key and Hash Diff) must be converted to string so that the concatenation occurs properly. Languages like PERL and PHP and Ruby will automatically convert the numeric (if there are any) and dates/times to strings. In all strongly typed languages (including SQL) the conversion must be cast by code.
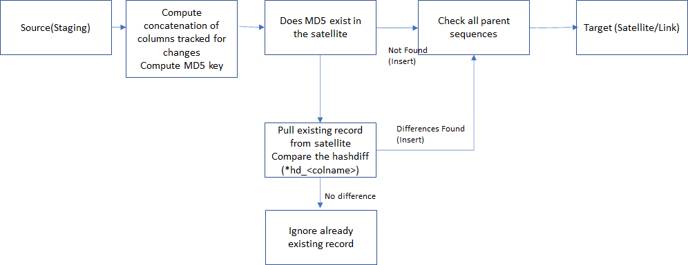
Hash Diff in ETL
Hash Difference tracks changes in columns in the Satellite. Include only those columns which will need to be tracked for deltas for. Adjustments must be made if the Satellite is modified, split, or merged. If any of those actions occur, then all Hash Difference values must be re-calculated across the entire Satellite for the currently active rows. This can take a lot of time, especially with Big Data.
The Hash Difference calculation can be made in real-time or in batch. It can be done pre-load to the staging area or during the load to the Data Vault. The ETL process flow for calculating MD5DIFF appears as follows:
Summary/Conclusion
Documenting some of the fundamental rules and standards around using MD5 within your Data Vault based EDW. Rules for Using MD5 Effectively:
- Always use a delimiter between fields – something other than a white space.
- Always use VARCHAR (non-national, non-unicode) but, if you MUST use uni-code, then make ALL your strings Unicode before calling the MD5 function.
- Ensure the ETL tool (or scripting language) character set encoding matches the database encoding.
- Stick to a 128-bit hash function for best performance.
- Use UPPER CASING if you want your MD5 result to be 'case-insensitive matching'.
Standards for MD5KEY and MD5DIFF
- Hash Key = REQUIRED PRACTICE (for DV2.0).
- Hash Difference = OPTIONAL PRACTICE.
- Add Hash Key to Link Structures and replicate to Link Satellites for best performance.
- Add Hash Difference to ALL Satellite structures (especially those with WIDE rows or MANY columns).
- Use Hash Key in Links and Link Satellites for Join Operations.
- Compute Hash Key and even, possibly, Hash Difference on the way IN to the staging area for the sake of expediency.
- If using Real-Time, compute Hash Key and Hash difference in the stream, add the columns to the transaction or message in the arrival queue.