Objectives:
The DataVault is a hub and spoke architecture that is easily scalable and can to a large extent be automated . In this whitepaper we will focus on the mechanisms that will be implemented to automate a Data Vault by using Zetaris models to infer the schema and keys for the Vault layers
Databases
A database is a structured collection of data with some implicit meaning. The data in a database is typically derived or collected from some real world source, and has an intended application. A database is made up of different tables, each table with columns that each represent a entity with a different data type. A row, or a tuple, of a table represents an instance of this table object.
Business Keys
Business keys are the unique attributes of data objects that can identify any given record in a dataset. A minimalistic approach is generally applied to a business key to maintain its uniqueness property. Note that a business key does not need to be a primary key.
Foreign Keys
In a relational schema , a foreign key represents the relation between two entities. It answers questions like Which is the parent object and which is the child object.
What is the nature of the relationship ? Is it a 1-to-1/1-to-many /many-to-many relationship. In the Data Vault world these relationships are key to establishing link tables or correlating between two hub tables
Volatility of data
Volatility is the measure of change. How frequently does the data in the data object change. A “name” field might rarely change in the lifetime of the record as compared to a “phone-number” field that has a probability of multiple changes over the life course of the record.
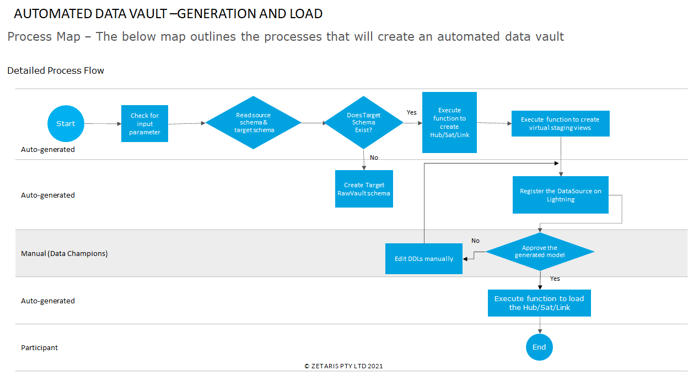
The Mechanism
The intention of the fluid data vault is to create and train models on existing data models so that we can enable the ability to infer a schema and relationships in case these are not made available explicitly. Based on these inferences , the system should be able to self-generate a proposed data vault model that will be made available for review to the end-users
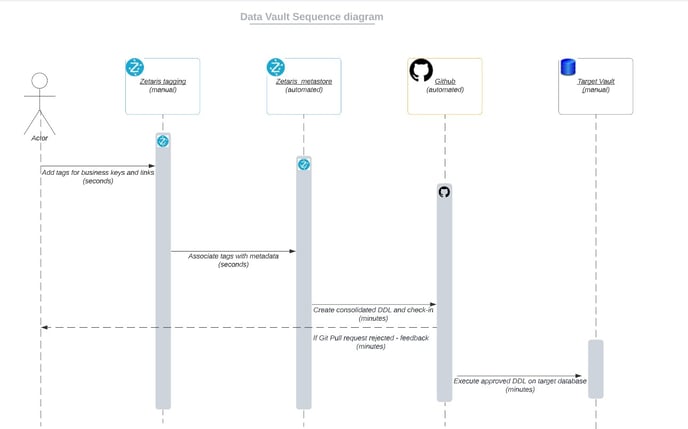
Technical Implementation
The steps mentioned below entails the creation of all the relevant hubs, sats and link tables for the fluid data vault on Zetaris UI.
Prerequisites:
-
Zetaris must have its metastore DB registered on the Lightning UI with a given name “metastore”.
-
JDBC credentials for the “metastore” datasource should be provided.
-
All the source databases must be registered on the lightning UI.
Please Note:
In this article,
1. The source databases are azure_mssql, aws_redshift and rds_postgresql.
2. The database where the data vault entities/tables are stored is named as ‘trial_vault’.
3. The container under which all the pipelines are created is named as ‘fluid_data_vault’.
Step1:
-
Create the pipeline named ‘create_hubs_stmts’
-
This pipeline generates the DDL statements for hub tables creation
-
It considers the main datasource as ‘azure_mssql’ and creates the same number of hub tables as the total number of tables in the ‘azure_mssql’ datasource
-
The only requirement here is to add a business key tag in all of the ‘azure_mssql’ tables
-
For example, the business key for the ‘customer’ table is ‘c_custkey’ and the tag added is ‘bk’
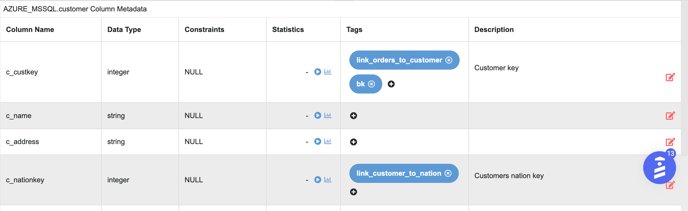 Business Key Tags
Business Key Tags -
Each of the create hub table statements has the below columns:
-
Business Key(s)
-
BKCC
-
Load Date
-
Record Source
-
MD5 Hash of Business Key(s) and BKCC (hk)
-
MD5 Hash of all the columns other than the business key(s) (hd)
-

-
Example Query
CREATE TABLE h_customer (hk_h_customer CHARACTER VARYING(100) NOT NULL, hd_h_customer CHARACTER VARYING(100) NOT NULL, c_custkey integer ,dss_load_date date NOT NULL, dss_record_source CHARACTER VARYING(100) NOT NULL, bkcc CHARACTER VARYING(100) NOT NULL) using trial_vault;
Step2:
-
Since we have three disparate sources from where we ingest data, we create three different pipelines
-
The pipelines are named ‘create_azure_sats_stmts’, ‘create_postgre_stg_stmts’ and ‘create_aws_redshift_sats_stmts’
-
These pipelines generate DDL statements for each of the satellite tables' creation
-
Each of the sat table names is suffixed with the source name (eg: ‘s_customer_azure_mssql’), where ‘customer' is the table name and 'azure_mssql’ is the source name
-
Each create sat table statement has the below columns:
-
All the columns of the table except for the business key(s)
-
Load Date
-
Record Source
-
BKCC
-
MD5 Hash of Business Key column(s) and BKCC (hk)
-
MD5 Hash of all the columns other than the business key column(s) (hd)
-

-
Example Query:
CREATE TABLE s_part_azure_mssql (hk_h_part CHARACTER VARYING(100) NOT NULL, hd_h_part CHARACTER VARYING(100) NOT NULL, p_type text, p_brand text, p_retailprice float, p_comment text, p_mfgr text, p_size integer, p_name text, p_container text ,dss_load_date date NOT NULL, dss_record_source CHARACTER VARYING(100) NOT NULL, bkcc CHARACTER VARYING(100) NOT NULL) using trial_vault;
Step3:
-
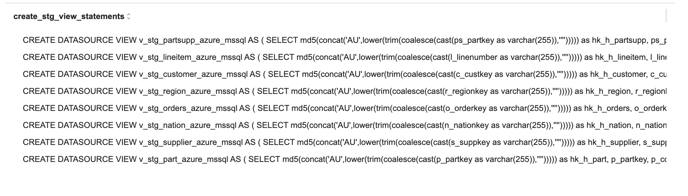
Since we have three disparate sources from where we ingest data, we create three different pipelines and the pipelines are named ‘create_aws_redshift_stg_stmts’, ‘create_azure_stg_stmts’ and ‘create_postgre_stg_stmts’
-
These pipelines generate the DDL statements for staging views creation and these views will be used as the source to insert data into the hubs and the satellites
-
Each of the staging view names is suffixed with the source name (eg: ‘v_stg_customer_azure_mssql’), where ‘customer' is the table name and 'azure_mssql’ is the source name
-
Each of the staging views has the below columns:
-
All the columns of the table
-
Load Date
-
Record Source
-
BKCC
-
MD5 Hash of Business Key(s) and BKCC (hk)
-
MD5 Hash of all the columns other than the business key(s) (hd)
-
-
Example Query:
CREATE DATASOURCE VIEW v_stg_partsupp_rds_postgresql AS ( SELECT md5(concat('USA',lower(trim(coalesce(cast(ps_partkey as varchar(255)),''''))))) as hk_h_partsupp, ps_partkey, ps_availqty, ps_suppkey, ps_supplycost, md5(concat(lower(trim(coalesce(cast(ps_suppkey as varchar(255)),''''))),lower(trim(coalesce(cast(ps_supplycost as varchar(255)),''''))),lower(trim(coalesce(cast(ps_availqty as varchar(255)),''''))))) as hd_h_partsupp, current_date() as dss_load_date, 'USA' as bkcc, 'rds_postgresql' as dss_record_source FROM rds_postgresql.partsupp);
-
Create the pipeline named ‘create_link_tbl_statements’
-
This pipeline generate the DDL statements for link tables creation
-
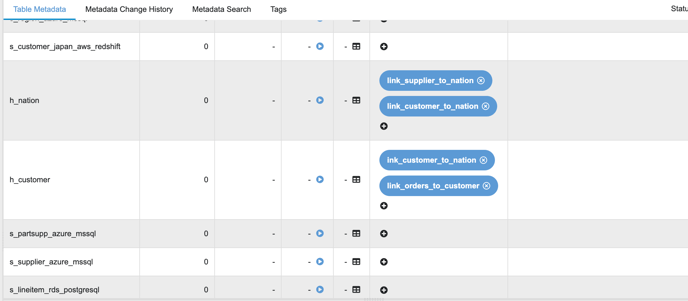
The only requirement here is to add a link tag in those hub tables between the tables we wish to connect/join
-
For example, if we want a link between the customer table and the nation table, then we add a tag ‘link_customer_to_nation’ in front of both ‘h_customer’ and ‘h_nation’
-
Each of the link table names contains multiple hub table names (eg: If we wish to create a link between customer and nation then the link table name will be ‘l_customer_nation’)

-
Example Query
CREATE TABLE l_customer_nation ( hk_h_link_customer_to_nation CHARACTER VARYING (100), n_nationkey integer, hk_h_nation text, dss_load_date date NOT NULL, dss_record_source CHARACTER VARYING(100) NOT NULL ) USING trial_vault;
Step5:
-
Since we have three disparate sources from where we ingest data, we create three different pipelines
-
The pipelines are named ‘create_aws_redshift_link_stg_stmts’, ‘create_azure_mssql_link_stg_stmts’ and ‘create_rds_postgresql_link_stg_stmts’
-
These pipelines generate the DDL statements for link staging views creation, and these views will be used as the source to insert data into the link tables
-
Each of the staging view name are suffixed with the source name (eg:‘v_stg_link_customer_nation_azure_mssql’), where ‘customer' and ‘nation’ are the table names and 'azure_mssql’ is the source name
-
All the connected tables must have a column tag which defines the relationship between the tables. For example, ‘customer’ and ‘nation’ table are related to each other based on 'nationkey'
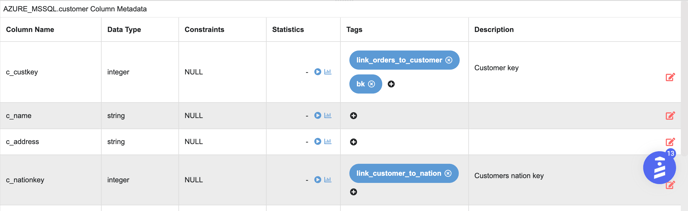
Column Level Link Tags-1
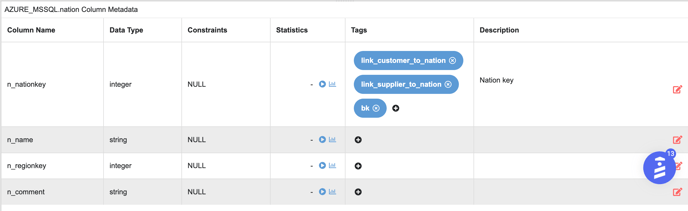 Column Level Link Tags-2
Column Level Link Tags-2-
Each of the staging views has the below columns:
-
Business keys of all the linked tables
-
Load Date
-
Record Source
-
BKCC
-
MD5 Hash of Business Key(s) of all the linked tables and BKCC (hk)
-
MD5 Hash of all the Business Key(s) of individual tables and BKCC
-
-
Example Query
CREATE DATASOURCE VIEW v_stg_link_supplier_to_nation_rds_postgresql AS ( SELECT md5(concat('USA', n_nationkey, s_suppkey)) as hk_h_link_supplier_to_nation, n_nationkey, s_suppkey, md5(concat('USA', lower(trim(coalesce(cast(s_suppkey as varchar(255)),''''))))) as hk_h_supplier, md5(concat('USA', lower(trim(coalesce(cast(n_nationkey as varchar(255)),''''))))) as hk_h_nation, NOW() as dss_load_date,'rds_postgresql' as dss_record_source FROM rds_postgresql.supplier, rds_postgresql.nation WHERE n_nationkey = s_nationkey);
Step6:
-
Since we have three disparate sources from where we ingest data, we create three different pipelines and, the pipelines are named ‘hubs_azure_insert_statements’, ‘hubs_postgre_insert_statements’ and ‘hubs_aws_redshift_insert_statements’
-
These pipelines generate the DML statements for inserting the data into the hubs from the staging views
-
The insert statements will only insert delta records in the hub table and these delta records are captured based on the MD5 hash (hk) in the source and target tables
-
Since hub tables are common across all the sources and there is a possibility the entity name might not be the same as the hub name, so we need to map the entity to the relevant hub name and therefore we add the tag ‘maps_to_*’ where * is the hub table name
-
For example, if the entity name is ‘customer_japan’, then we should map it to the customer hub and add the tag ‘maps_to_customer’
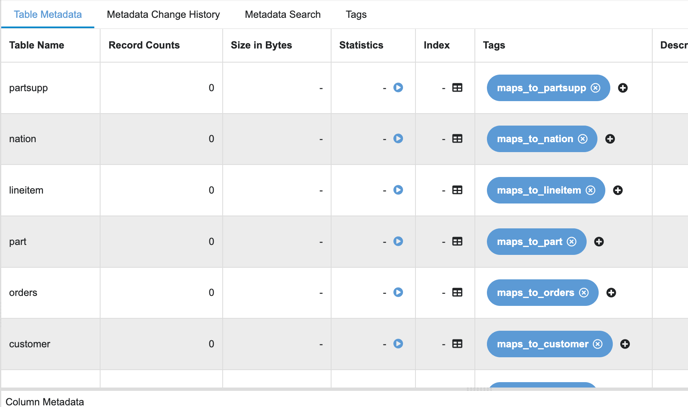 Hubs Mapping Table Level Tags
Hubs Mapping Table Level Tags
-
Example Query
INSERT INTO trial_vault.h_partsupp (ps_partkey, hk_h_partsupp, hd_h_partsupp ,dss_load_date, dss_record_source, bkcc) SELECT vstg.ps_partkey, vstg.hk_h_partsupp, vstg.hd_h_partsupp ,vstg.dss_load_date, vstg.dss_record_source, vstg.bkcc FROM v_stg_partsupp_rds_postgresql vstg LEFT JOIN trial_vault.h_partsupp htab ON vstg.hk_h_partsupp=htab.hk_h_partsupp WHERE htab.hk_h_partsupp IS NULL;
Step7:
-
Since we have three disparate sources from where we ingest data, we create three different pipelines
-
The pipelines are named ‘sats_aws_redshift_insert_stmts’, ‘sats_azure_insert_stmts’ and ‘sats_postgre_insert_stmts’
-
These pipelines generate the DML statements for inserting the data into the sats from the staging views
-
The insert statements will only insert delta records in the sat table and these delta records are captured based on the MD5 hash (hk) in the source and target tables
-
Example Query
INSERT INTO trial_vault.s_customer_japan_aws_redshift (bkcc, c_name, c_phone, dss_load_date, dss_record_source, hd_h_customer_japan, hk_h_customer_japan) SELECT vstg.bkcc, vstg.c_name, vstg.c_phone, vstg.dss_load_date, vstg.dss_record_source, vstg.hd_h_customer_japan, vstg.hk_h_customer_japan FROM v_stg_customer_japan_aws_redshift vstg LEFT JOIN trial_vault.s_customer_japan_aws_redshift stab ON vstg.hd_h_customer_japan=stab.hd_h_customer_japan WHERE stab.hd_h_customer_japan IS NULL;
Step8:
-
Since we have three disparate sources from where we ingest data, we create three different pipelines
-
The pipelines are named ‘links_azure_insert_statements’, ‘links_aws_redshift_insert_statements’ and ‘links_azure_insert_statements’
-
These pipelines generate the DML statements for inserting the data into the sats from the staging views
-
The insert statements will only insert delta records in the link table, and these delta records are captured based on the MD5 hash (hk_h_link) in the source and target tables
-
Example Query:
INSERT INTO trial_vault.l_supplier_nation (dss_record_source, hk_h_supplier, n_nationkey, dss_load_date, s_suppkey, hk_h_link_supplier_to_nation, hk_h_nation) SELECT vstg.dss_record_source ,vstg.hk_h_supplier ,vstg.n_nationkey ,vstg.dss_load_date ,vstg.s_suppkey ,vstg.hk_h_link_supplier_to_nation ,vstg.hk_h_nation FROM v_stg_link_supplier_to_nation_azure_mssql vstg LEFT JOIN trial_vault.l_supplier_nation ltab ON vstg.hk_h_link_supplier_to_nation = ltab.hk_h_link_supplier_to_nation WHERE ltab.hk_h_link_supplier_to_nation IS NULL;
Step9:
-
Create a git repository named ‘RawVault’
-
Add a branch named ‘ddl_dml_statements’ along with the ‘main’ branch where we can store all the statements generated from the above pipelines and store them as seperate file
-
Generate a token from
https://github.com/settings/tokens - Connect your Github account and save the token
-
Add a branch protection rule for main branch. The rule we need to tick is 'Require a pull request before merging'
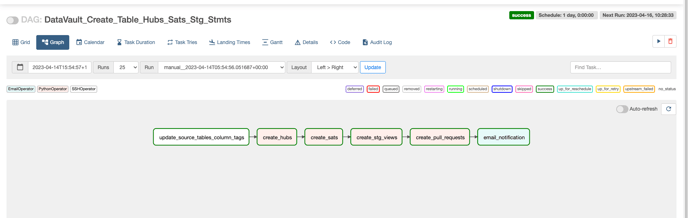
Step10:
-
create an airflow DAG named ‘DataVault_Create_Table_Hubs_Sats_Stg_Stmts’ on the airflow UI which generates the ‘CREATE TABLE’ and ‘CREATE VIEW’ statements for Hubs and Satellites and also stores the files in GitHub ‘ddl_dml_statements’ branch and generates a pull request to merge the changes into the ‘main’ branch, along with the email notification stating that the DAG execution was a success or a failure
Step11:
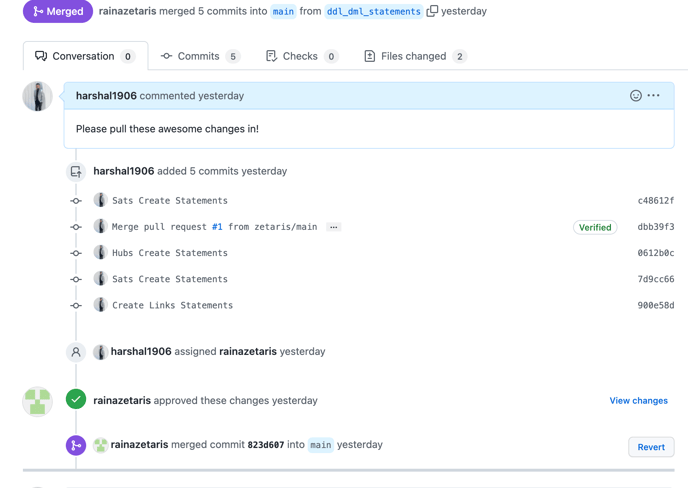
-
The developer will then assign the pull request to the relevant authority/approver and after the approver has approved the pull request, the final changes in the Data Vault Schema (DDL/DML statements) will be merged into the ‘main’ branch
Step12:
-
Once the changes are approved and merged into the main branch, create an airflow DAG named ‘DataVault_Execute_Create_Table_Hubs_Sats_Stg_Stmts’ on the airflow UI which executes all the create statements (both hubs & sats tables and staging views) on the Zetaris UI via the API
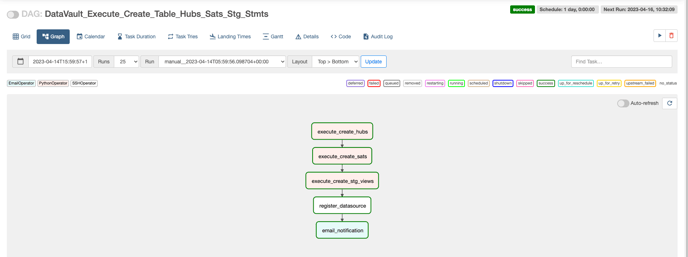 DAG - DataVault_Execute_Create_Table_Hubs_Sats_Stg_Stmts
DAG - DataVault_Execute_Create_Table_Hubs_Sats_Stg_Stmts
Step13:
-
After the hubs & sats entities (tables & views) are created by scheduling the DAG created in Step 12, create another DAG named ‘DataVault_Create_Table_Links_Stg_Stmts’ on the airflow UI which generates the ‘CREATE TABLE’ and ‘CREATE VIEW’ statements for Links and also stores the files in GitHub ‘ddl_dml_statements’ branch and generates a pull request to merge the changes into the ‘main’ branch
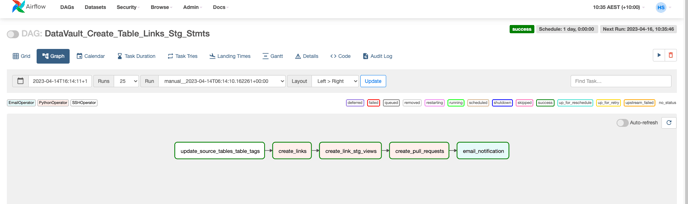 DAG - DataVault_Create_Table_Links_Stg_Stmts
DAG - DataVault_Create_Table_Links_Stg_Stmts
Step14:
-
Once the changes are approved and merged into the main branch, create an airflow DAG named ‘DataVault_Execute_Create_Table_Links_Stg_Stmts’ on the airflow UI which executes all the create statements (link tables and staging views) on the Zetaris UI via the API
Step15:
-
After the hubs, sats & links entities (tables & views) are created by scheduling the DAGS created in previous steps, create another DAG named ‘DataVault_Create_Hubs_Sats_Links_Insert_Stmts’ on the airflow UI which generates the ‘INSERT INTO TABLE’ statements for Hubs, Sats & Links and also stores the files in GitHub ‘ddl_dml_statements’ branch and generates a pull request to merge the changes into the ‘main’ branch
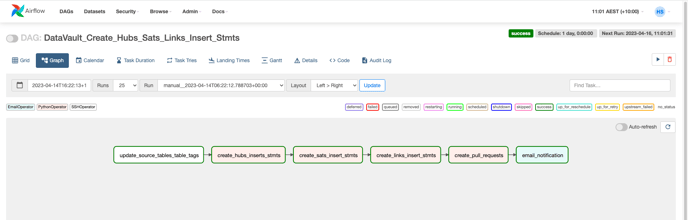
Step16:
-
Once the changes are approved and merged into the main branch, create an airflow DAG named ‘DataVault_Execute_Insert_Statements’ on the airflow UI which executes all the insert statements on the Zetaris UI via the API
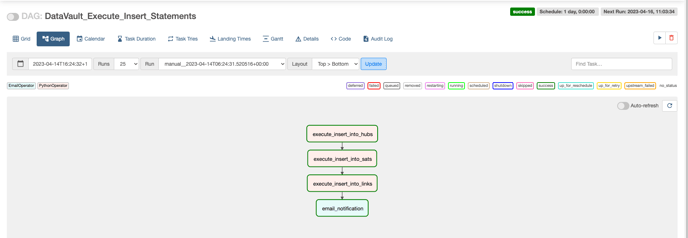
DAG - DataVault_Execute_Insert_Statements
Step17:
-
If there any changes to the existing satellite tables, after the changes are made in the source tables, execute the DAG named ‘DataVault_Create_Sats_Alter_Stmts’ on the airflow UI which checks whether the modifications for the columns are additions or deletions and generates alter table statements accordingly on the Zetaris UI via the API
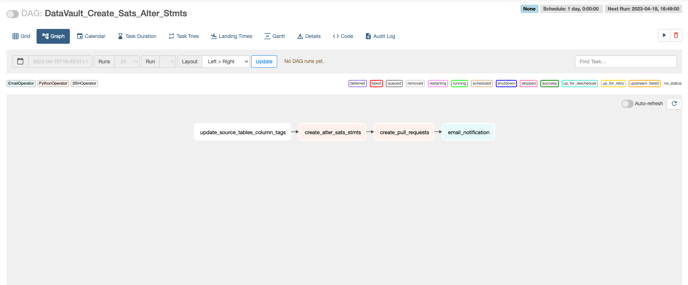
Step18:
-
Once the changes are approved and merged into the main branch, create an airflow DAG named ‘DataVault_Execute_Sats_AlterStmts’ on the airflow UI which executes all the insert statements on the Zetaris UI via the API
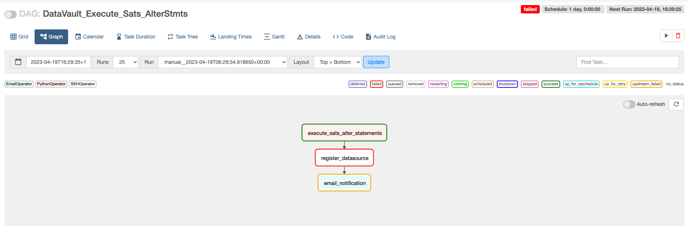 DAG - DataVault_Execute_Sats_AlterStmts
DAG - DataVault_Execute_Sats_AlterStmts
Step 17 , Step 18 and Step 19 are required only if we need to make changes to the data vault. For example, modifying existing sat table, adding a new hub or a link table and their corresponding staging views.
Step19:
-
Execute all the dags mentioned from Step10 to Step18, if we need to:
-
Add new hub tables
-
Add new link tables
-
Add new sat tables
-
Modify corresponding Staging Views
-
Insert the new data into hubs, sats and links
-