What Zetaris is doing at a high-level:
-
Ingest meta data from the data source
-
Scan data from data source, and transfer it over network
-
Evaluate SQL function; projection, aggregation, join and run built in function.
In order for Zetaris to do these well, we make sure we deploy the optimal query execution framework:
Scan Source Data
-
Identify the best scan strategy, for example, index scan, full table scan, etc. It depends on how source data base deal with underlying data. We call it data source aware optimizer.
-
Scan less data if possible as it hits network bandwidth. We can do this by pushdown predicate/aggregation to data source.
-
Scan data as fast as possible. We can do this by doing parallel scan by leveraging partitioning source table.
-
Cache scanned data into local storage(main memory, block storage). We are doing this explicitly or implicitly; adaptive cache. We called it our cache aware optimizer .
State-of-the-Art Query Optimizer
-
NDP leverages Spark SQL catalyst query optimizer.
-
Rule Base Optimizer
Come up with more than hundreds rules to minimize tree manipulation. -
Cost Base Optimizer
Decide join type(Sort Merge Join, Hash Join, broadcast join) as well as join order. -
Whole Stage Code Generator
Generate optimized byte code at runtime improving performance compared to interpreted execution. whole-stage codegen which collapses an entire query into a single function
Adaptive Query Execution
-
Our cost-based optimization framework collects and leverages a variety of data statistics (e.g., row count, number of distinct values, NULL values, max/min values, etc.) to help Spark choose better plans.
-
Adaptive Query Execution reoptimizes and adjust query plans.
Adaptive Query Execution supports:
-
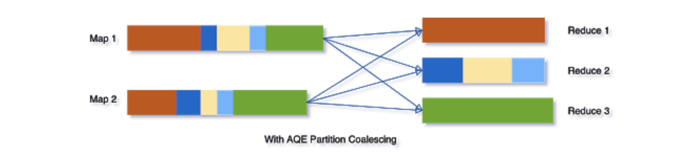
Dynamically coalescing shuffle partitions
When running queries in Spark to deal with very large data, shuffle usually has a very important impact on query performance among many other things.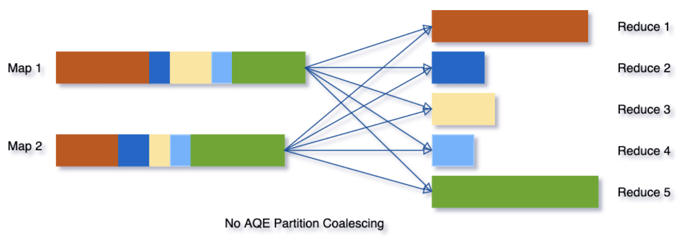
-
Dynamically switching join strategies
replans the join strategy at runtime based on the most accurate join relation size.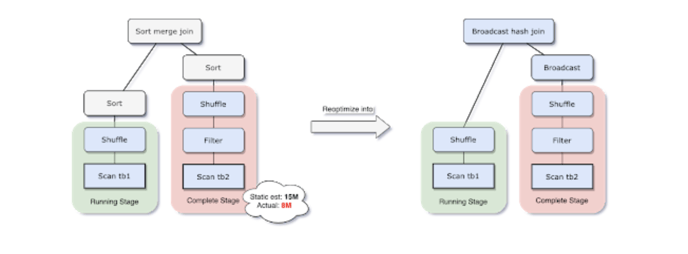

-
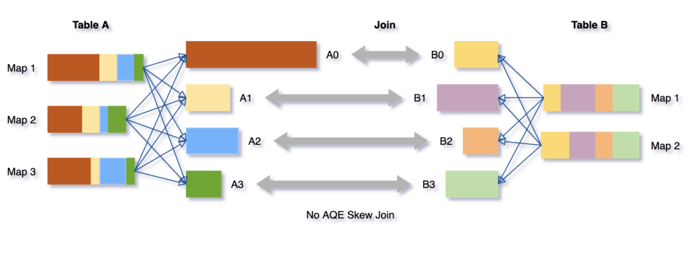
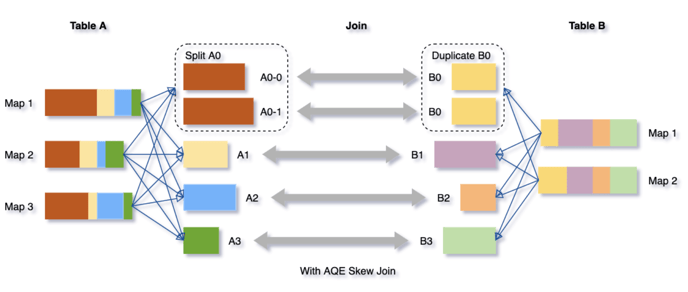
Dynamically optimizing skew joins
Data skew occurs when data is unevenly distributed among partitions in the cluster. Severe skew can significantly downgrade query performance, especially with joins. AQE skew join optimization detects such skew automatically from shuffle file statistics. It then splits the skewed partitions into smaller subpartitions, which will be joined to the corresponding partition from the other side respectively.