Query Director in Zetaris is a feature that enables multi-engine query routing. It supports parallel deployment and configuration of Spark and Presto (Trino-based) engines for optimized query management in data environments with diverse processing needs.
Technical Features
-
Multi-engine orchestration enables users to optimize each query’s execution based on workload, resource requirements, and cost.
-
Direct frontend engine configuration simplifies admin tasks.
-
Query redirect constructs (
using Presto, etc.) allow granular control over query execution paths. -
Role-based access and workload partitioning safeguard resource utilization and maintain clear team boundaries.
-
Flexible cluster architecture with auto-scaling supports both high-performance analytics and heavy ETL pipelines.
Engine Setup & Configuration Steps
1. Accessing Engine Configurations:
- Go to the Compute Engine section in Zetaris admin.
![]()
- Click "Add Engine".
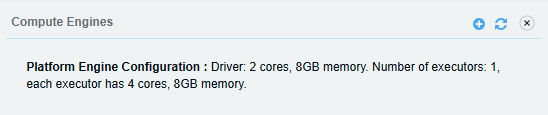
- Choose engine type: Spark or Presto.
-
You can define multiple engines (e.g., two Presto engines for different use cases)

-
2. Engine Parameters:
-
Specify:
-
Node count (parallel execution)
-
Memory allocation (16GB, 32GB, etc.)
-
Executor details (worker threads/subtasks)

-
-
Adjust max records and other tuning settings via GUI.
-
Enable cluster auto-scaling.
-
Set maximum node limits for dynamic scaling (e.g., “max 50 nodes”).
Once all the details are filled. click on Create and that will create the required engine.

4. Query Routing & Engine Selection
-
By default, queries route to Spark. You will be able to see the created engine in the dropdown in SQL workspace.

-
You can either select from dropdown the required engine or use explicit constructs (e.g.,
using Presto) in queries to redirect to other engines.
SELECT * FROM TPCDS_DBA.call_center using spark sparktest
5. Making changes to the engine
- You can perform multiple actions like starting/stopping the engine, delete and edit the engine configuration in the Details section.

-
You monitor the status of the worker and the engine compute usage in here to make sure the load is well balanced across the nodes.
- In the Details tab, changes to the engine configuration can be made to adjust to the load.

6. Assigning users and roles to an engine
Query Director in Zetaris allows admin to route specific users and roles to a dedicated engine to get efficient performance on query run and limit unnecessary usage on heavyy compute engines.
- Assigning users to an engine
- In the users tab on the selected engine, you will see the option to search for any registered user and assign to this particular engine.
- This ensures that the selected user is only able to run their queries on the assigned engine.

- Assigning roles to an engine
- Zetaris allows you to allocate engines to existing roles in the data hub.
- Simply search for the role and assign it to the selected engine and all users tagged under this role will by default be using the assigned engine.

7. Technical Differentiation
Table below demonstrates the key technical differences between the two engines and the best workload use cases for each of them.
| Criteria | Spark Engine | Presto Engine |
|---|---|---|
| Query Type | Batch, ETL, Transform-heavy, ML | Interactive, Analytics, Federation |
| Memory Handling | Supports disk spillover (fault-tolerant) | In-memory only (high latency if out of memory) |
| Scalability | Checkpoints, resilient, large jobs | Fast joins, multi-source analytics |
| Configuration | Tunable via frontend | Tunable via frontend |
| Example Workload | Complex case statements, aggregations | Cross-table joins, fast analytical queries |