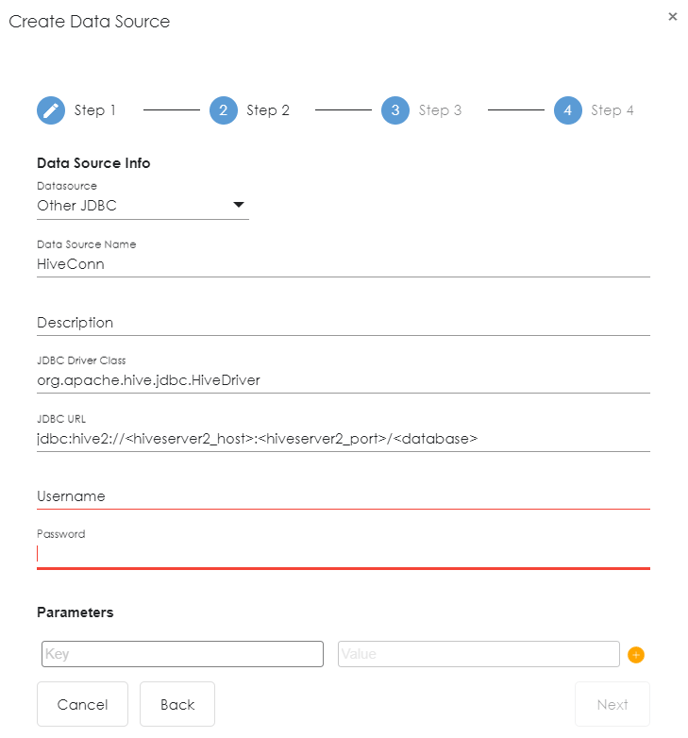
The JDBC Connector to retrieve data from Hive can be configured using the “Other JDBC” option. A JDBC named query can be used to submit a custom SQL query to Hive and retrieve the results using the JDBC Connector.
This topic describes how to configure the Hive JDBC Connector to access Hive. When Hive is configured for access with JDBC, the Hive user impersonation setting must be taken into account, as well as whether or not the Hadoop cluster is secured with Kerberos.
JDBC Server Configuration
The JDBC Connector is installed with the JAR files required to access Hive via JDBC, hive-jdbc-<version>.jar and hive-service-<version>.jar, and automatically registers these JARs.
When a JDBC server is configured for Hive access, the JDBC driver class name must be specified, database URL, and client credentials just like configuring a client connection to an SQL database.
To access Hive via JDBC, the following properties must be specified and values in the jdbc-site.xml server configuration file must be entered:
|
Property |
Value |
|---|---|
|
jdbc.driver |
org.apache.hive.jdbc.HiveDriver |
|
jdbc.url |
jdbc:hive2://<hiveserver2_host>:<hiveserver2_port>/<database> |
The value of the HiveServer2 authentication (hive.server2.authentication) and impersonation (hive.server2.enable.doAs) properties, and whether or not the Hive service is utilizing Kerberos authentication, will inform the setting of other JDBC server configuration properties. These properties are defined in the hive-site.xml configuration file in the Hadoop cluster. It will be needed to obtain the values of these properties.
Hive JDBC Driver
The latest Hive JDBC driver can be downloaded from the Maven Hive JDBC driver repository
Download the driver and place it in /opt/zetaris/server/lightning/jdbc-lib/ inside the server container
Loading Hive JDBC driver into Zetaris
Step 1: Start the container/service
Step 2: Download the driver
Step 3: Place it in /home/zetaris/.../jdbc-lib/
Step 4: Stop container /service
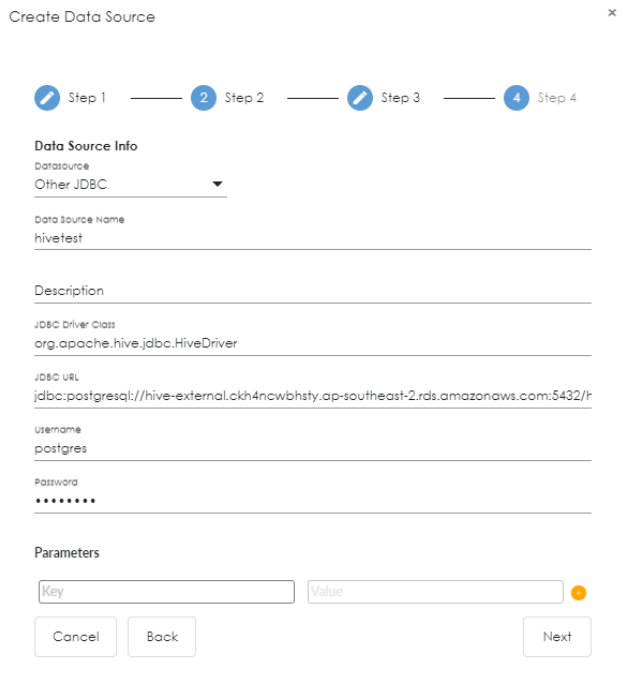
Example: Connection pane window from the NDP Data Fabric Builder connecting to Hive: