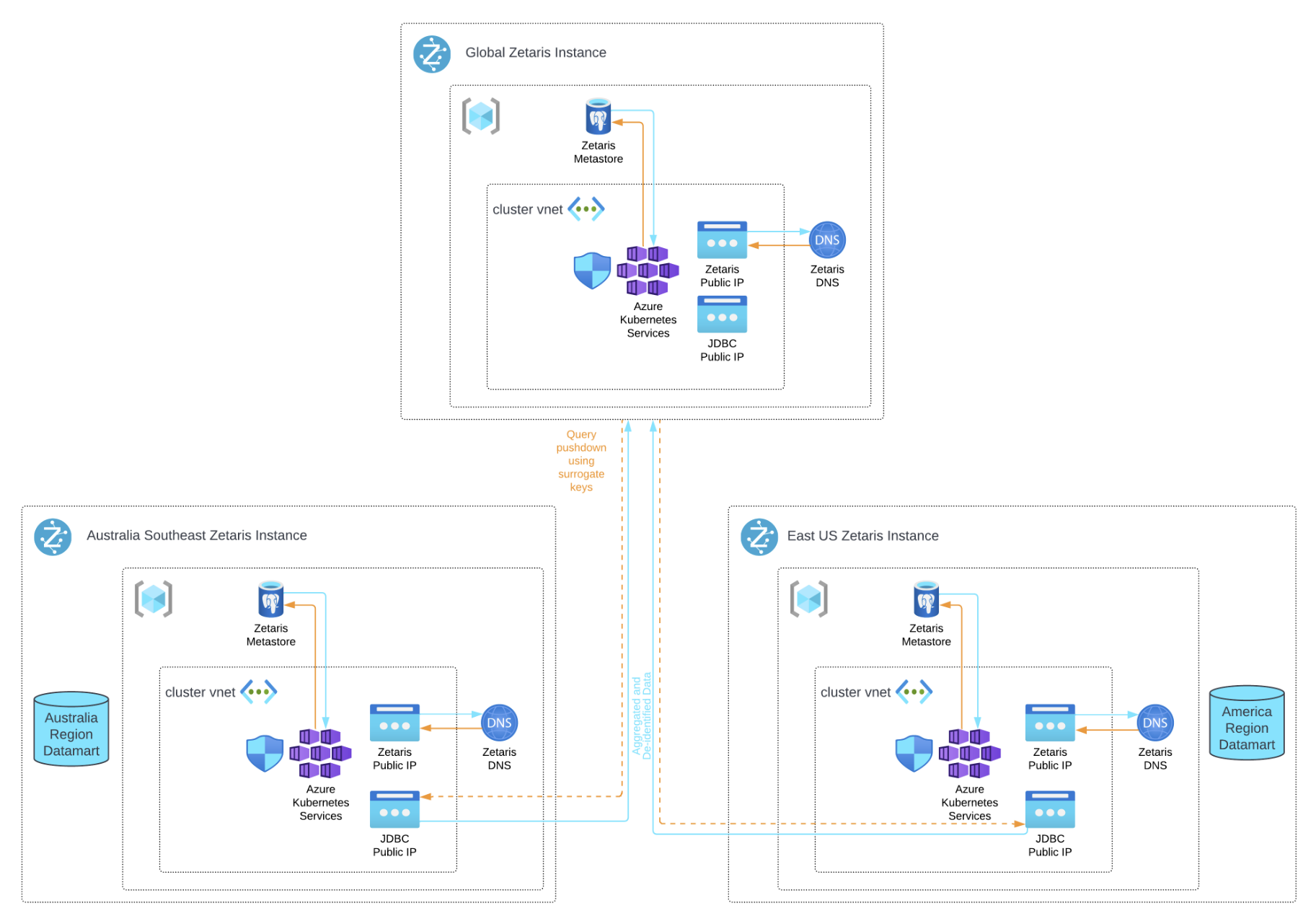
Infrastructure Diagram
Configuring the Zetaris environments
Configuring the Nation-based Zetaris Instances
In this example, we are working with 3 regions. The Singapore region is assumed to be the headquarters and there are two regional reporting entities in Australia and the US.
In each of the country or region , there will be a standard installation of Zetaris Networked Data Platform
In our case a standard installation was completed in both the Australia Southeast region and East US region to demonstrate the Credit Bureau datasets for each region. The headquarters are assumed to be in the Singapore region and each of the Australia and US regions' aggregated and anonymized datamarts are provisioned into the Singapore Zetaris
Configuring the Global Zetaris Instance
When setting up the Global environment this must be added to the lightning-server-deployment.yaml under the following path:
deps:
jars:
...
- local:///home/zetaris/lightning/jdbc-driver/ndp-jdbc-driver-2.1.0.13-driver.jar
This will enable Zetaris to utilize its JDBC driver to connect with other Zetaris platforms
Configuring the JDBC connection on Kubernetes
To allow for JDBC connectivity, each environment will be required to open port 10000. This can be done by adding the following to the end of the lightning-server-service.yaml.
---
apiVersion: v1
kind: Service
metadata:
name: lightning-jdbc-driver-svc
namespace: default
spec:
type: LoadBalancer
ports:
- port: 10000
name: lightning
targetPort: 10000
selector:
app: lightning-server
Setting up the dataset in the regions (US and Australia)
- Upload the respective country/region datasets to Zetaris using the NDP File System.
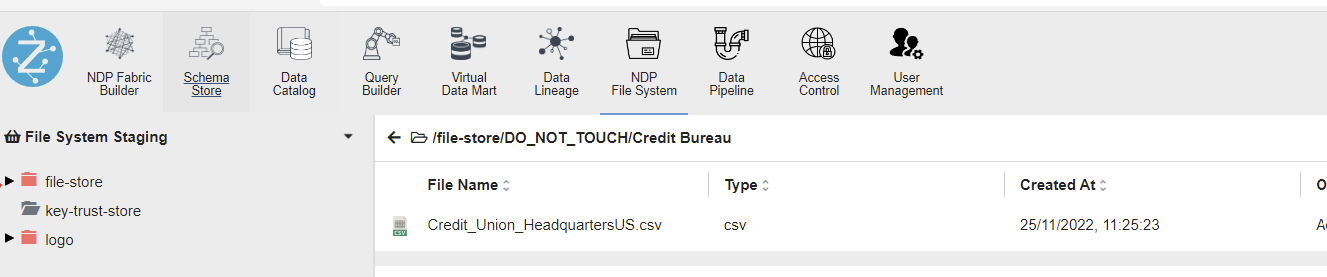
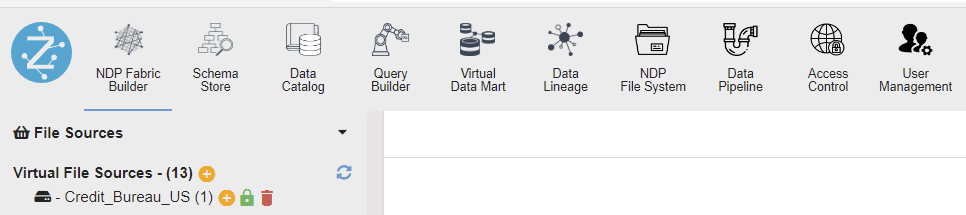
- Navigate to the NDP Fabric Builder feature tab.
-
Add a Virtual File Source using the dataset files uploaded in step 1.
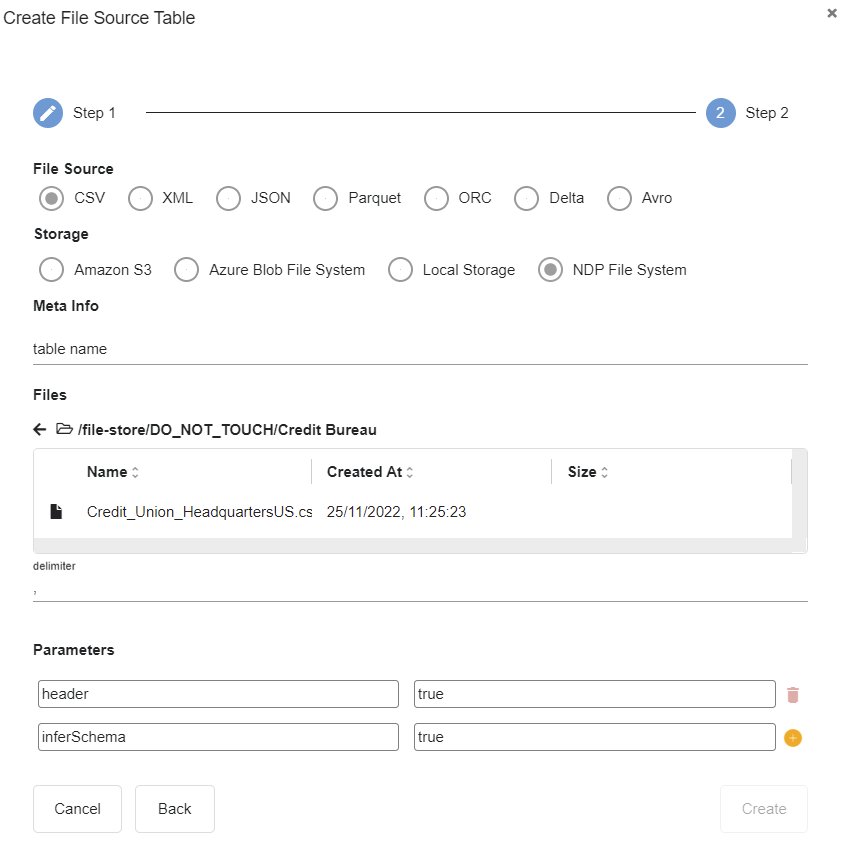
-
Upon successful registration, the registered dataset can be previewed and inspected as shown below:

The dataset can be aggregated in a pipeline of query builder and associated with a VDM (virtual datamart).
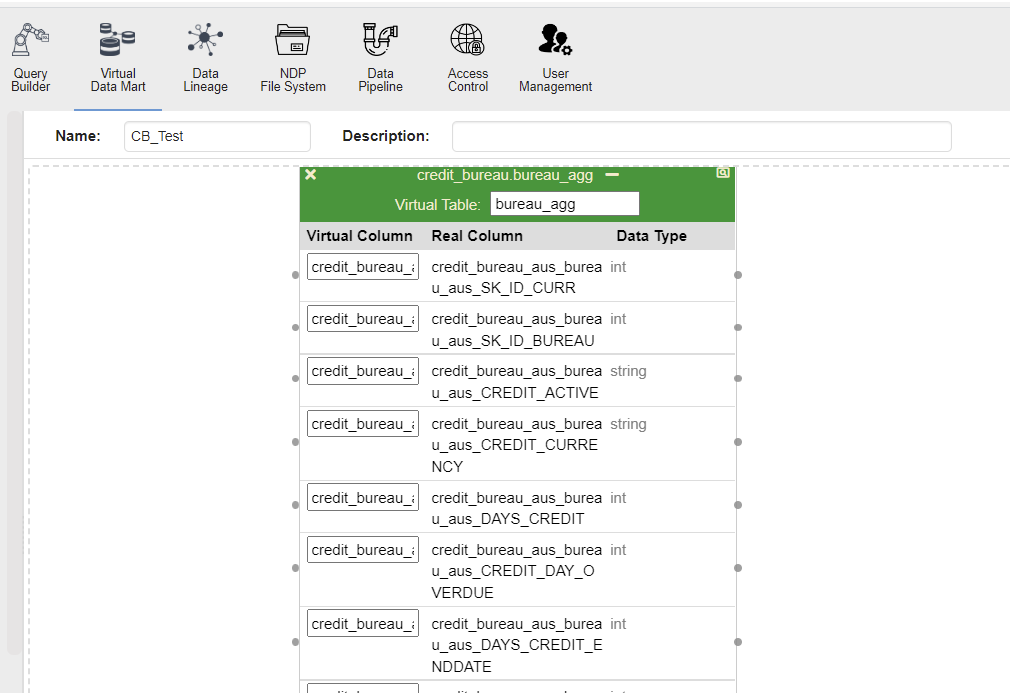
The user access management needs to be set-up carefully to ensure that the global instance of Zetaris have the right privileges and avoid any direct access to the raw data in the regions
Navigate to the User Management feature tab
Assign the global user to the global role
Navigate to the Access Control feature tab
Select the previously created data mart
Assign the global role select privileges
etting up the dataset for the global (Singapore) instance
Intention
In order to adhere to GDPR, data pipelines are created to ensure that the global admin account receives de-identified data with its corresponding aggregated data. Providing the global admin account the means to join the aggregated data of both countries to create a cumulative view.
Connecting to the National Zetaris Instances from the Global Zetaris Instance
Using Lightning Wizard
-
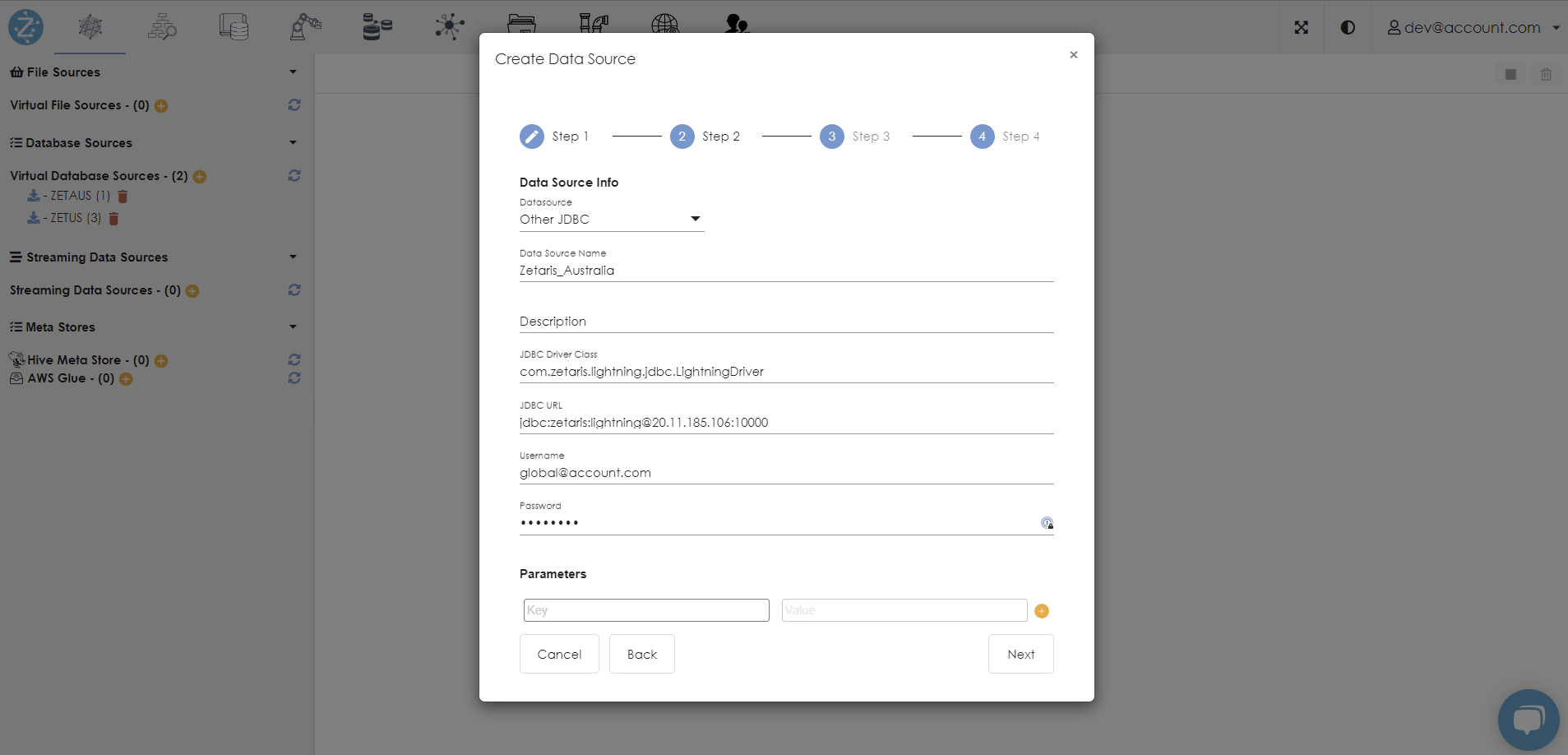
Create a new virtual data source connection within Zetaris.
-
Datasource: Other JDBC
-
Datasource Name: CB_<Region>
-
JDBC Driver Class: com.zetaris.lightning.jdbc.LightningDriver
-
JDBC URI: jdbc:zetaris:lightning@<JDBC-LoadBalancer-IP>:10000
-
e.g. jdbc:zetaris:lightning@10.0.0.0:10000
-
-
username: global account username
-
password
-
-
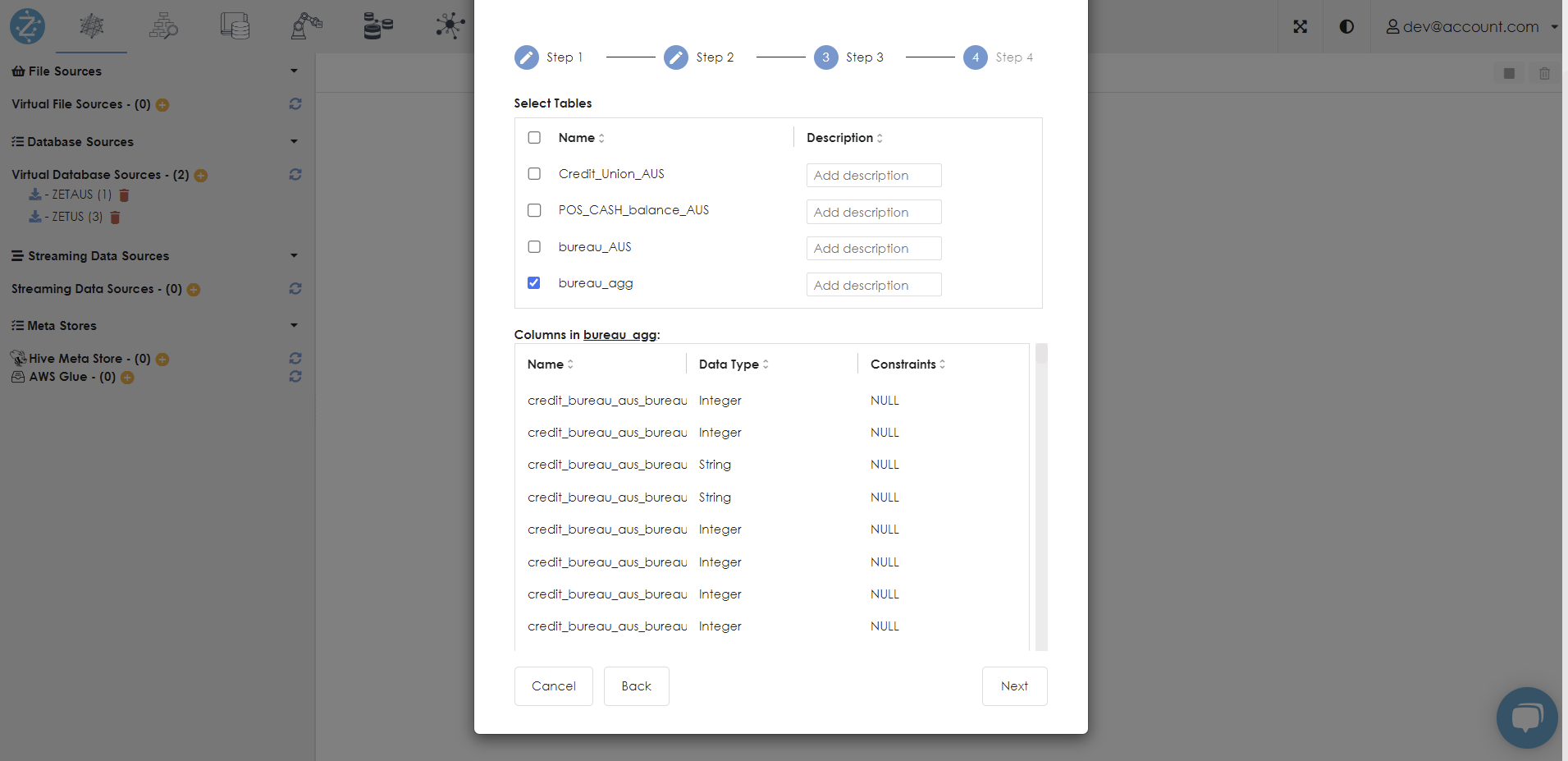
Select Next, then select the Pipeline/Permanent View for the aggregated data.
-
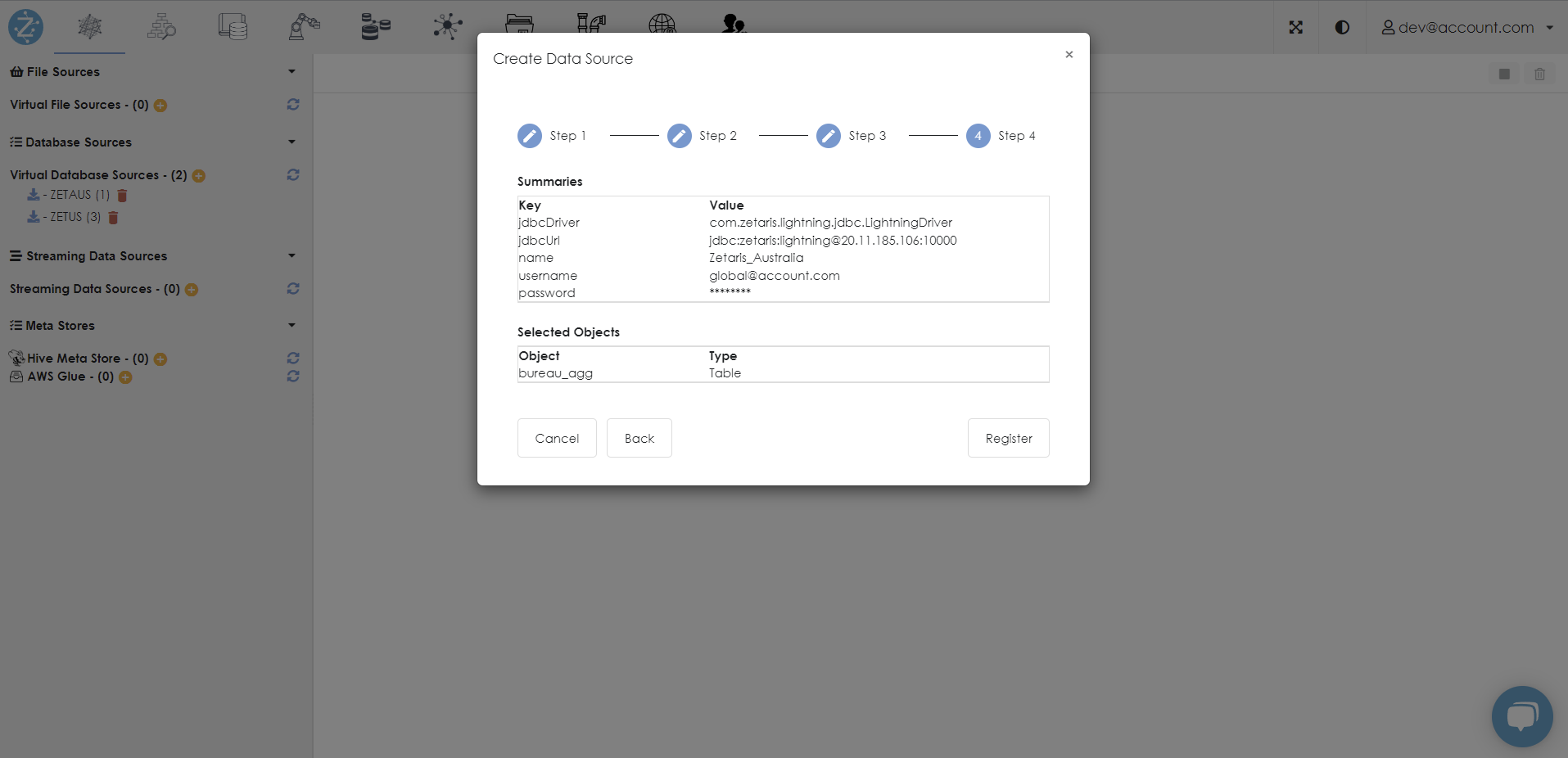
Select Next to validate the data and register the datasource.
Using SQL Editor
- Navigate to the Schema Store feature tab.
- Run the following queries for each region:
CREATE DATASOURCE CU_<country/region> DESCRIBE BY "CU_<country/region>" OPTIONS (
jdbcdriver "com.zetaris.lightning.jdbc.LightningDriver",
jdbcurl "jdbc:zetaris:lightning@<JDBC-LoadBalancer-IP>:10000",
username "<global_username>",
password "<global_password>"
);
REGISTER DATASOURCE TABLES FROM CU_<country/region>; - The final connections will be displayed as seen below:
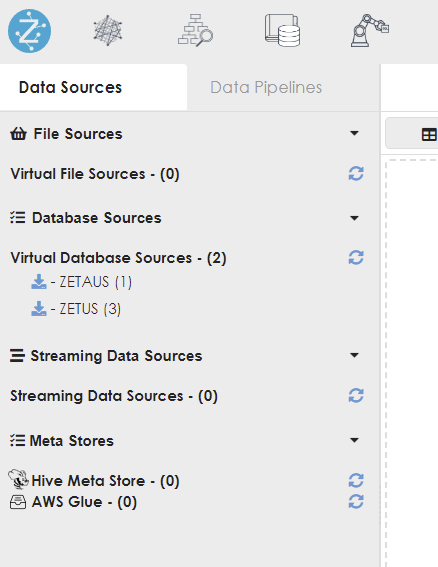
- The access controls for the global user will need to be set-up as shown below:
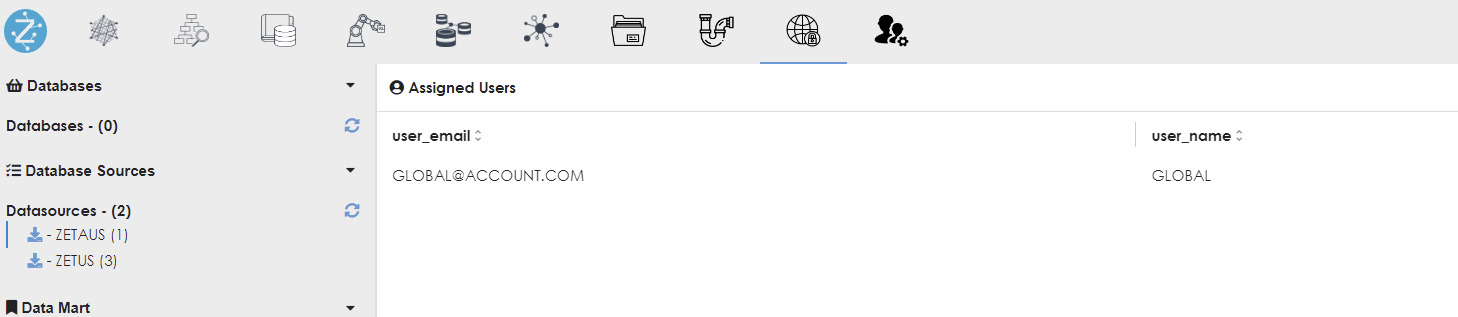
Provisioning access using the same authorization used in the US and Australia data mart -
To complete the reporting process, the aggregated datasets can be joined together using the common surrogate key to create a global view of the individual’s credit information.
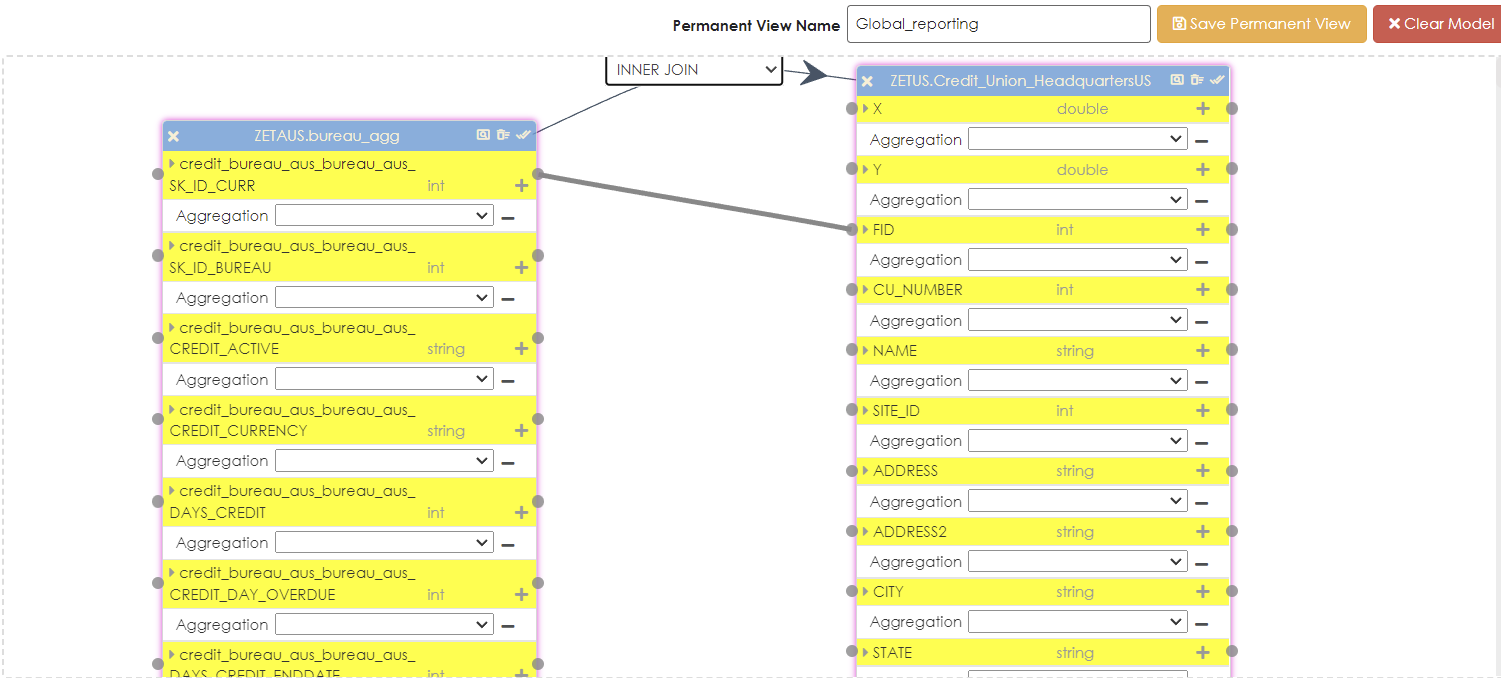
Aggregated permanent view to be used in reporting or ML algorithms for PD calculation