Consider the following logical data model below:
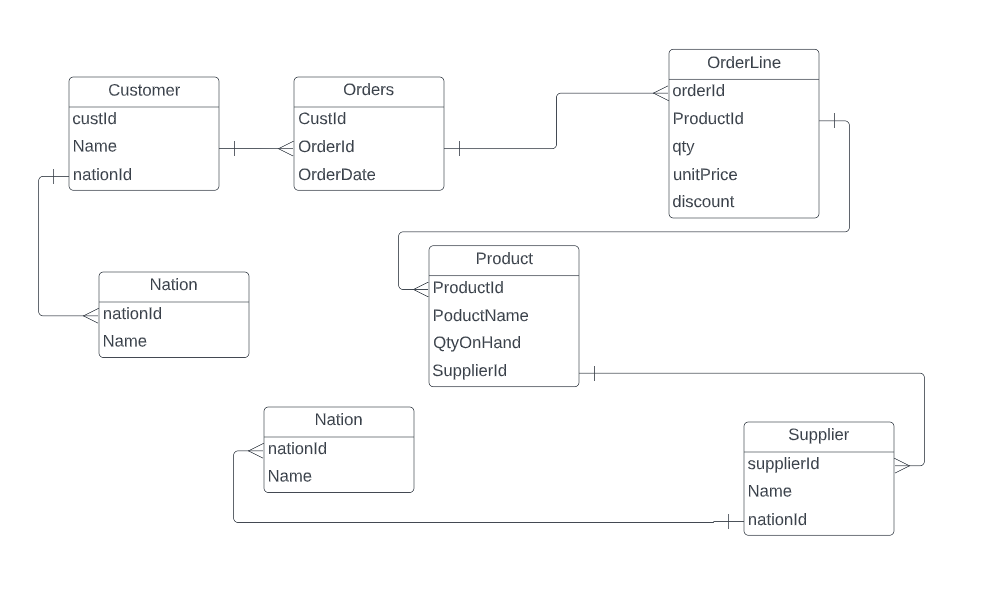
If we wanted to extract the top supplier per country for any given product set, we would write an analytical query. Now let's assume that there are:
- 1 trillion Order Line items,
- 100 billion orders across
- 20 countries, servicing
- 20 million customers.
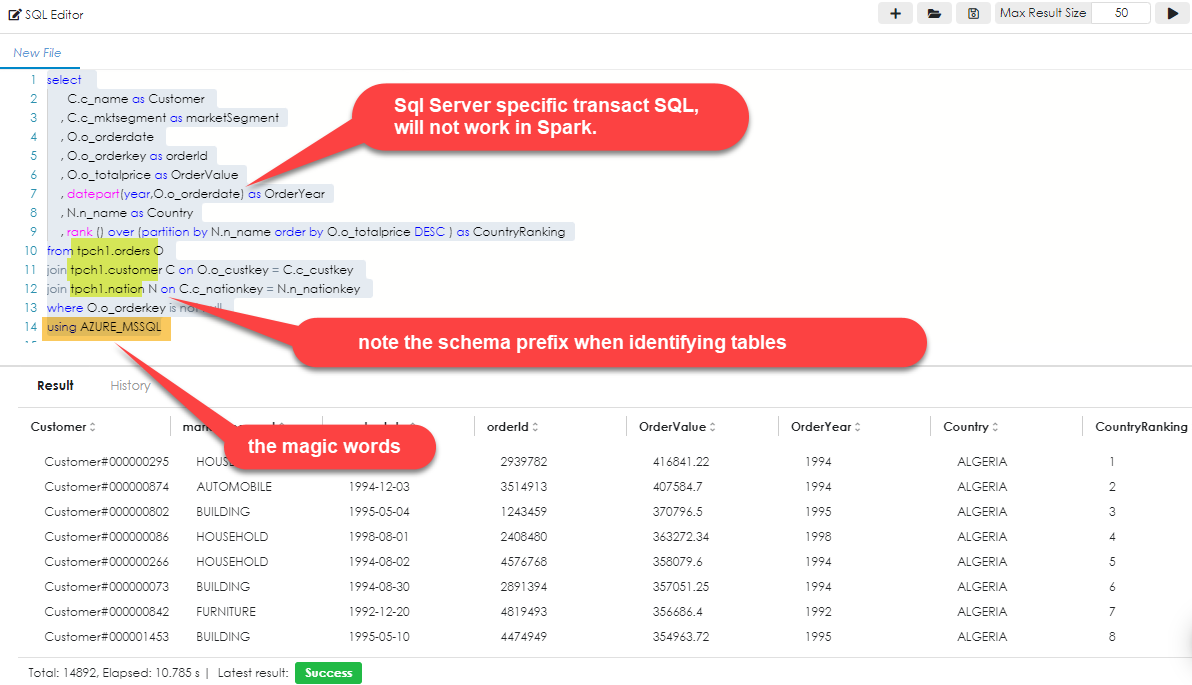
With numbers like this, it is imperative that we only retrieve the summary dataset and DO NOT join the tables inside Zetaris (on Spark). Thus when we write a query, it absolutely needs to run entirely on the source data and return just the dataset. In Zetaris, this is achieved with the "using <DataSourceName> " suffix operator.
Method
Inspect the datasource for this query to be run against and determine if there is a schema. This is achieved in the Sql command editor with:
describe master datasource <DataSourceName>
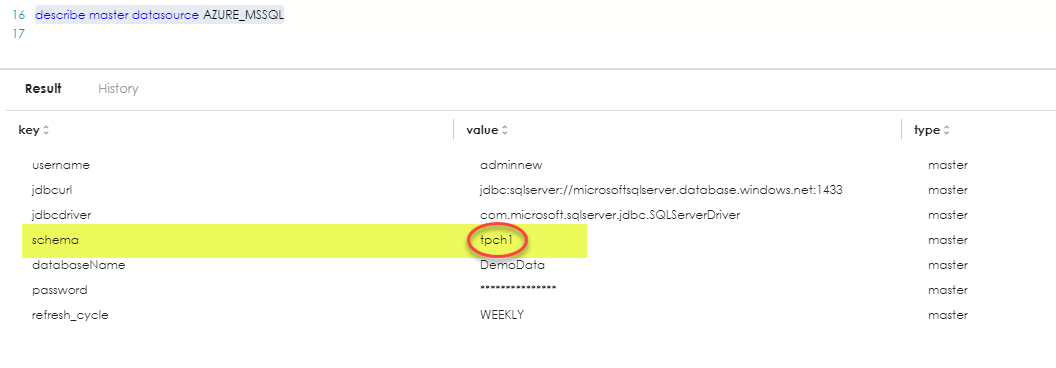
Note the schema name. In the case of the example above, it is "tpch1". This schema prefix will need to be added to each table / view name from the source environment.
Limitations
This does not work on subqueries or CTE's (Common Table Expressions), as these are usually not the last pieces of code written in a query. If the example above, you will see that the using operator is the very last thing to be specified. If any other code is found after this, it will cause the query to fail.
You cannot pass parameters to this query. So if this is a pipeline object, there is no way to dynamically filter the SQL using a dateset from a pervious operation.